夏乙 發自 凹非寺
量子位 出品 | 公眾號 QbitAI

搞定一種語言之後,是不是很希望算法能在近百種語言上無縫遷移?
AI真能無師自通,對於我們這些“因為語言不通而分散在各處”的人們來說,簡直是天大的福音。
新鮮出爐的Facebook“多語種句嵌入”,就是這樣一種“神器”。他們提出了一種新架構,為橫跨34個語族、28種不同文字寫成的的93種語言,學習了統一的聯合多語種句嵌入。
舉個例子,只要用標注好的英語數據訓練一個分類器算法,教會它判斷一個英語句子是不是少兒不宜,就可以無縫遷移到其他語言上,不管你是豪薩語、韃靼語還是漢語粵方言,它都能判斷有沒有少兒不宜。
能一下子準備好接受這麽多種語言,是怎麽做到的呢?
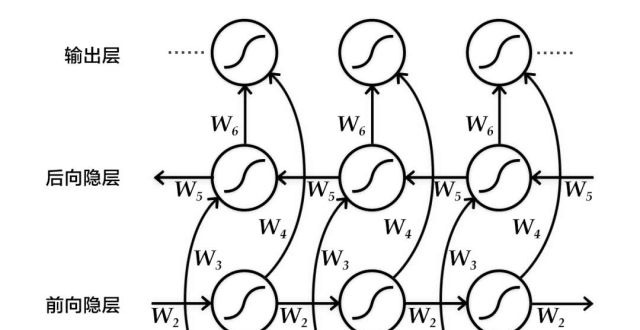
我們來看一下這個系統的架構:

它由編碼器(encoder)、解碼器(decoder)兩大部分組成。其中,編碼器是個無關語種的BiLSTM,負責構建句嵌入,這些句嵌入接下來會通過線性變來換初始化LSTM解碼器。
為了讓這樣一對編碼器、解碼器能處理所有語言,還有個小條件:編碼器最好不知道輸入的究竟是什麽語言,這樣才能學會獨立於語種的表示。所以,還要從所有輸入語料中學習出一個“比特對嵌入詞庫”(BPE)。
不過,解碼器又有著完全相反的需求:它得知道輸入的究竟是什麽語言,才能得出相應的輸出。於是,Facebook就為解碼器附加了一項輸入:語言ID,也就是上圖的Lid。
訓練這樣一個系統,Facebook用了16個NVIDIAV100 GPU,將batch size設定為12.8萬個token,花5天時間訓練了17個周期。
架構說起來不算複雜,效果怎麽樣呢?

用包含14種語言的跨語種自然語言推斷數據集(cross-lingual natural language inference,簡稱XNLI)來測試,這種多語種句嵌入(上圖的Proposed method)零數據(Zero-Shot)遷移成績,在其中13種語言上都創造了新紀錄,只有西班牙語例外。
另外,Facebook用其他任務測試了這個系統,包括ML-Doc數據集上的分類任務、BUCC雙語文本數據挖掘。他們還在收集了眾多外語學習者翻譯例句的Tatoeba數據集基礎上,製造了一個122種語言對齊句子的測試集,來證明自家算法在多語言相似度搜索任務上的能力。
最後,附上傳送門~
論文:

Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond
Mikel Artetxe, Holger Schwenk
https://arxiv.org/pdf/1812.10464.pdf
代碼也即將開源,會直接更新到Facebook之前放出的無關語種句嵌入庫LASER中:
https://github.com/facebookresearch/LASER
—完—
年度評選報名
加入社群
量子位AI社群開始招募啦,歡迎對AI感興趣的同學,在量子位公眾號(QbitAI)對話界面回復關鍵字“交流群”,獲取入群方式;
此外,量子位專業細分群(自動駕駛、CV、NLP、機器學習等)正在招募,面向正在從事相關領域的工程師及研究人員。
進專業群請在量子位公眾號(QbitAI)對話界面回復關鍵字“專業群”,獲取入群方式。(專業群審核較嚴,敬請諒解)
誠摯招聘
量子位正在招募編輯/記者,工作地點在北京中關村。期待有才氣、有熱情的同學加入我們!相關細節,請在量子位公眾號(QbitAI)對話界面,回復“招聘”兩個字。
喜歡就點「好看」吧 !