翻栗子 發自 凹非寺
量子位 出品 | 公眾號 QbitAI
在我們的世界裡,谷歌翻譯是這樣的:
一直被調戲的翻譯娘
在谷歌的世界裡,谷歌翻譯是這樣的:
西語英語:你不問,就不會知道了
請注意,視頻裡的文字只是為了便於觀賞,才存在的。
而AI在翻譯語音的時候,不把西語的音頻轉成文本,也不生成任何英語的文本,直接產出了英文音頻。和標答一字不差。
這是谷歌團隊的最新成果,想法大膽而有效。

仿佛在雙語環境裡出生的小朋友,還沒識字,就能把爸爸說的話翻譯給媽媽。
怎麽會不用看文本?
這個翻譯模型,名字叫做S2ST(全稱Speech-to-Speech Translation) 。
不看文本只靠聽,背後的原理是把一種語音的聲譜圖(Spectrogram) ,映射到另一種語音的聲譜圖上。
那麽,聲譜圖什麽樣?
下圖就是 (西語) “你好麽,嘿,我是威廉,你怎麽樣啊?”的聲譜圖。
橫軸是時間,縱軸是Mel頻率
然後是目標,英文的聲譜圖。
AI只要從大量的成對數據裡,學懂英文和西語的聲譜映射關係,就算不識別人類說的是什麽字,依然能當上翻譯員。
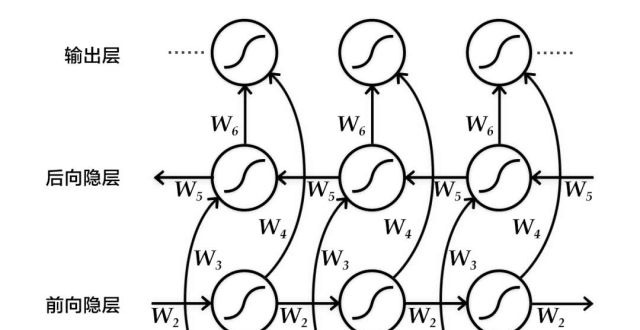
當然,一個完整的翻譯模型,並沒有上面說的這麽簡單,它由三個部分組成:
一是基於注意力的序列到序列 (seq2seq) 神經網絡。就是下圖的藍色部分,它負責生成目標聲譜圖,這只是第一步,還不是音頻;
二是一個聲碼器(Vocoder) 。下圖的紅色部分,它會把聲譜圖轉換成時域波形 (Time-Domain Waveforms) ,這已經是帶有時間順序的正經聲波了;
三是個可選的附加功能,原本說話人的編碼器。綠色部分,經過它的加工,翻譯出的英文,和原本的西語,聽上去就像同一個人發出來的。

當然,藍色部分還是主角。
裡面的編碼器 (左) ,是8層雙向LSTM堆起來的;而解碼器 (Spectrogram Decoder) ,團隊說要選4-6層LSTM的,深一點效果比較好。
成功了
模型是用人類自發的對話 (比如打電話的語音) 端到端訓練出來的,一起來看看成果吧。
第一題,短語。“克蘭菲爾德大學的新員工”,翻譯和標答一字不差。
原文:nuevos empleados de Cranfield University
標答:New hires at Cranfield University
第二題,句子。“看看這個國家上下,你看到了什麽”,依然和標答一致。
原文:Por lo tanto, mirar alrededor del país y lo que ves.
標答:So, look around the country and whatdoyou see?
對手表現怎樣?借助轉換文本來翻譯的AI,缺了個“do”字:

第三題,帶從句的句子。“我的表 (堂) 兄弟姐妹們小的時候,我照顧過他們也教過他們,有過一些這樣的經歷。”
原文:Tengo cierta experiencia en cuidar y ense?ar a mis primos cuando eran jóvenes.
標答:I’ve got some experience in looking after and teaching my cousins when they were young.
照顧(TakingCare of) 有缺失,其他部分對比標答是完整的。
再看對手,“照顧 (Care) ”和“教 (Teach) ”都用了動詞原形,語法不是很嚴格:

肉眼看過之後,再讓S2ST和先轉換文本再翻譯的AI對比一下BLEU分。
在“Conversational”大數據集上,S2ST的BLEU分比對手差了6分:42.7比48.7。

的確還有一些差距,但畢竟對手依靠了文本,算是開卷考了。
這樣說來,直接跳過文本的想法,雖然聽起來有些飄,但結果證明是可行的。
所以,谷歌團隊說,大有可為啊。
論文傳送門:
https://arxiv.org/pdf/1904.06037.pdf
更多樣本傳送門:
https://google-research.github.io/lingvo-lab/translatotron/
—完—
活動報名|多模態視頻人物識別
加入社群
量子位AI社群開始招募啦,量子位社群分:AI討論群、AI+行業群、AI技術群;
歡迎對AI感興趣的同學,在量子位公眾號(QbitAI)對話界面回復關鍵字“微信群”,獲取入群方式。(技術群與AI+行業群需經過審核,審核較嚴,敬請諒解)
喜歡就點「好看」吧 !