作者:Ilya Pestov
英語版譯者:Vasily Zubarev
中文版譯者:Panda
實現高品質機器翻譯的夢想已經存在了很多年,很多科學家都為這一夢想貢獻了自己的時間和心力。從早期的基於規則的機器翻譯到如今廣泛應用的神經機器翻譯,機器翻譯的水準不斷提升,已經能滿足很多場景的基本應用需求了。近日,Ilya Pestov 用俄語寫的機器翻譯介紹文章經 Vasily Zubarev 翻譯後發表到了 Vas3k.com 上。機器之心又經授權將其轉譯成了漢語。希望有一天,機器自己就能幫助我們完成這樣的任務。
俄語版:http://vas3k.ru/blog/machine_translation/
英語版:http://vas3k.com/blog/machine_translation/
我打開谷歌翻譯的頻率是打開 Facebook 的兩倍,價格標簽的即時翻譯對我而言再也不是賽博朋克了。這已經成為了現實。很難想象這是機器翻譯算法百年研發之戰的結果,而且在那段時間的一半時間裡其實都沒什麽明顯的成功。
我在本文中討論的確切發展將立足於所有的現代語言處理系統——從搜索引擎到聲控微波。我將探討的是當今的在線翻譯技術的演化和結構。

P. P. Troyanskii 的翻譯機器(根據描述繪製的圖片。很遺憾沒有照片留下。)
起初
故事開始於 1933 年。蘇聯科學家 Peter Troyanskii 向蘇聯科學院提交了《用於在將一種語言翻譯成另一種語言時選擇和列印詞的機器》。這項發明非常簡單——它有四種語言的卡片、一台打字機和一台舊式膠片相機。
操作員先取文本的第一個詞,然後找到對應的卡片,拍一張照片,再在打字機上鍵入其形態特徵(名詞、複數、性別等)。這台打字機的按鍵編碼了其中一項特徵。打字帶和相機膠片是同時使用的,從而得到一組帶有詞及它們的形態的幀。

儘管看起來很不錯,但和蘇聯的很多事情都一樣,人們認為這項發明是「沒用的」。Troyanskii 用了 20 年時間試圖完成他的發明,之後因心絞痛逝世。在 1956 年兩位蘇聯科學家找到他的父母之前,這世上沒人知道這種機器。
那是冷戰的鐵幕剛剛降下的時候。在 1954 年 1 月 7 日,IBM 在紐約的總部啟動了 Georgetown-IBM 實驗。IBM 701 電腦有史以來第一次自動將 60 個俄語句子翻譯成了英語。
「一位不認識任何一個蘇聯語言詞匯的女孩在 IBM 卡片上敲出了這些俄語消息。這個「大腦」以每秒兩行半的驚人速度在一台自動印表機上趕製出了它的英語翻譯。」——IBM 的新聞稿

IBM 701
但是,宣告勝利的頭條新聞裡卻隱藏了一個小小的細節。沒人提到這些翻譯得到的樣本是經過精心挑選和測試過的,從而排除了歧義性。對於日常使用而言,該系統並不比口袋裡的常用語手冊更好。儘管如此,軍備競賽還是開始了:加拿大、德國、法國以及(特別是)日本全都加入到了機器翻譯競賽中。
機器翻譯競賽
改進機器翻譯的徒勞工作持續了四十年之久。1966 年,US ALPAC 在其著名的報告中稱機器翻譯是昂貴的、不準確的和毫無希望的。他們轉而建議將重點放在詞典開發上,這將美國研究者排除在了競賽之外近十年時間。
即便如此,僅憑科學家和他們的嘗試、研究和開發,現代自然語言處理的基礎還是建立了起來。多虧了這些彼此監視的國家,當今所有的搜索引擎、垃圾資訊過濾器和個人助理都出現了。

基於規則的機器翻譯(RBMT)
最早的基於規則的機器翻譯思想出現於 70 年代。科學家研究了翻譯員的工作,試圖讓當時還極其緩慢的電腦也能重複這些行為。這些系統包含:
雙語詞典(比如,俄語->英語)
每種語言一套語言學規則(比如,以 -heit、-keit、-ung 等特定後綴結尾的名詞都是陰性詞)
這就是這種系統的全部。如有需要,該系統還能得到一些補充,比如增加姓名列表、拚寫糾錯器和音譯功能。

PROMPT 和 Systran 是 RBMT 系統中最有名的案例。如果你想感受下那個黃金時代的柔和氣息,去試試 Aliexpress 吧。
但即使它們也有一些細微差別和亞種。
直接機器翻譯
這是機器翻譯中最直接的類型。它會將文本分成詞,然後翻譯這些詞,再稍微校正一下形態,最後協調句法得到結果;或多或少聽起來還行。當太陽落山後,訓練有素的語言學家還在為每個詞編寫規則。
其輸出會返回某種類型的翻譯結果。通常情況下,結果很糟糕。就好像是這些語言學家白白浪費了自己的時間。
現代系統完全不會使用這種方法,現代語言學家對此感激不盡。

基於遷移的機器翻譯
與直接翻譯相比,我們翻譯時要做準備——首先確定句子的語法結構,就像上學時老師教的那樣。然後我們再操作整個結構,而不是一個個的詞。這有助於在翻譯中得到相當好的詞序轉換。理論上是這樣。
但在實踐中,這仍然會得到逐詞翻譯的結果並會讓語言學家身疲力竭。一方面,它帶來的是簡化過的一般性語法規則。但另一方面,由於詞結構的數量比單個的詞要多得多,所以這又會變得更加複雜。

語際機器翻譯
在這種方法中,源文本會被轉換成中間表征,並且會被統一用於全世界的所有語言(中間語言)。這正是笛卡爾所夢想的那種中間語言:一種元語言,遵循普適的規則並且可以將翻譯變成一種簡單的「來回切換」任務。接下來,中間語言可以轉換成任何目標語言,而這就是奇點!
正是由於存在這種轉換,所以語際機器翻譯常常會和基於遷移的系統混淆。語際機器翻譯的不同之處是語言學規則是針對每種單獨的語言和中間語言的,而不是針對語言對。這意味著我們可以向語際系統加入第三種語言並且在它們三者之間彼此翻譯。而我們無法在基於遷移的系統中做到這一點。

看起來很完美,但實際並不。創建這樣一種通用的中間語言極其困難——很多科學家都在這上面投入了一生。他們還沒有取得成功,但多虧了他們,我們現在有了形態層面、句法層面、甚至語義層面的表征。但只有語義-文本理論(Meaning-text theory)耗費了巨資!
中間語言的思想還會再回來的。讓我們再等等看。

如你所見,所有的 RBMT 都很蠢笨和可怕,所以它們很少得到使用,除了一些特定的案例(比如氣象報告翻譯等)。RBMT 最常被提及的優點有形態準確性(不會混淆詞)、結果的可再現性(所有翻譯器的結果都一樣)和調節到特定學科領域的能力(比如為了教授經濟學家或特定於程式員的術語)。
就算有人真的成功創造出了一個完美的 RBMT,語言學家也用所有的拚寫規則強化了它,但還是會存在某些例外情況:英語中的不規則動詞、德語中的可分前綴、俄語中的後綴以及人們的表達方式存在差異的情況。任何試圖涵蓋所有細微差別的行為都會耗費數以百萬小時計的工作時間。
還不要忘記多義詞。同一個詞在不同的語境中可能會具有不同的含義,這會得到不同的翻譯結果。你試試能從這句話中理解到幾種含義:I saw a man on a hill with a telescope?
語言不會按照什麽固定的規則而發展——語言學家倒是喜歡這個事實。過去三百年中的侵略活動對語言的影響非常大。你怎麽能向機器解釋這一點?
四十年的冷戰沒能幫助找到任何明確的解決方案。RBMT 已死。
基於實例的機器翻譯(EBMT)
日本對機器翻譯競賽尤其感興趣。原因不是冷戰,而另有其它:這個國家理解英語的人非常少。這在即將到來的全球化方面是一個很嚴重的問題。所以日本人非常積極地想要找到一種可行的機器翻譯方法。
基於規則的英日翻譯極其複雜。這兩種語言的語言結構完全不一樣,幾乎所有詞都需要重新排列,而且還需要添加新詞。1984 年,京都大學的長尾真提出了一個思想:使用現成的短語而不是重複進行翻譯。
假設我們想翻譯一個簡單的句子——「I'm going to the cinema.」而且我們之前已經翻譯了一個類似的句子——「I'm going to the theater.」而且我們也能在詞典中找到「cinema」這個詞。
那麽我們只需找到這兩個句子的不同之處、翻譯缺失的詞、不要搞錯了即可。我們擁有的實例越多,翻譯結果就會越好。
我正是採用這種方式構建了下面的我不熟悉的外語短語!

EBMT 讓全世界的科學家看到了方向:事實證明,你可以直接向機器輸入已有的翻譯,而不必花費多年時間構建規則和例外。革命還沒有發生,但顯然已經邁出了第一步。革命性的統計機器翻譯發明將在那之後短短五年內誕生。
統計機器翻譯(SMT)
1990 年初,IBM 研究中心首次展示了一個對規則和語言學一無所知的機器翻譯系統。它分析了兩種語言的相似文本並且試圖理解其中的模式。

這是一個簡潔而又優美的思想。兩種語言中的同一句子被分成單詞,然後再進行匹配。這種操作重複了近 5 億次,記錄下了很多模式,比如「Das Haus」被翻譯成「house」或「building」或「construction」等詞的次數。
如果大多數時候源詞都被翻譯成「house」,那麽機器就會使用這一結果。注意我們沒有使用任何規則,也沒有使用任何詞典——所有的結論都是由機器完成的,其指導方針是統計結果和這樣的邏輯——「如果人們這樣翻譯,我也這樣翻譯」。統計翻譯由此誕生。

這個方法比之前的所有方法都更加有效和準確。而且無需語言學家。我們使用的文本越多,我們得到的翻譯結果就越好。

谷歌的統計翻譯內部情況示例。它不僅給出了概率,而且還顯示了反向翻譯結果統計
仍然還有一個遺留問題:機器該怎樣將「Das Haus」與「building」對應起來呢——我們又怎麽知道翻譯結果是正確的?
答案是我們沒法知道。一開始,機器會假設「Das Haus」一詞與來自翻譯句子的任意詞都有同等的關聯。接下來,當「Das Haus」出現在其它句子中時,與「house」關聯的數量會增多。這就是詞對齊算法,這是大學級機器翻譯的典型任務之一。
機器需要成百萬上千萬的雙語句子才能收集到每個詞的相關統計結果。我們如何得到這些數據?好吧,我們決定取用歐洲議會和聯合國安理會會議的摘錄,這些都是以所有成員國的語言提供的,而且可供下載:
UN Corpora:https://catalog.ldc.upenn.edu/LDC2013T06
Europarl Corpora:http://www.statmt.org/europarl
基於詞的 SMT
一開始的時候,最早期的統計翻譯系統的工作方式是將句子分成詞,因為這種方法很直觀而且符合邏輯。IBM 的第一個統計翻譯模型被稱為 Model 1。名字也相當優雅,對吧?猜猜他們的第二個模型叫什麽?
Model 1:逐詞對應

Model 1 使用了一種經典方法來將句子分成詞和記錄統計資訊。這個過程不考慮詞序。唯一要用的技巧是將一個詞翻譯成多個詞。比如「Der Staubsauger」可能會變成「Vacuum Cleaner」,但並不意味著反過來也可以。
這裡有一些基於 Python 的簡單實現:https://github.com/shawa/IBM-Model-1
Model 2:考慮句子中的詞序

缺乏語言詞序知識是 Model 1 的一個問題,而且這個問題在某些情況下很重要。
Model 2 解決了這個問題:它記憶了輸出句子中詞通常出現的位置,並且會通過一個中間步驟將詞排列成更自然的形式。結果變得更好了,但仍然不盡人意。
Model 3:額外增添

翻譯結果中常常會出現新詞,比如德語的冠詞或英語否定句中的「do」。比如「Ich will keine Persimonen」→「I do not want Persimmons.」為了解決這個問題,Model 3 又增加了兩個步驟:
如果機器認為有加入新詞的必要性,則插入 NULL 標記
為每個標記詞的對齊選擇合適的小品詞或詞
Model 4:詞對齊
Model 2 考慮了詞對齊,但對詞序重排一無所知。比如,形容詞常會與名詞交換位置,所以不管詞序記憶得多好,都不會讓輸出結果更好。因此,Model 4 考慮了所謂的「相對順序」——如果兩個詞總是交換位置,模型就能學到。
Model 5:修正錯誤
這裡沒什麽新鮮的。Model 5 所要學習的參數更多了,而且修正了詞位置衝突的問題。
儘管基於詞的系統本身是革命性的,但它們仍然無法處理格、性和同義詞。每一個詞都只有單一一種翻譯方式。現在我們已經不再使用這種系統了,因為它們已經被更為先進的基於短語的方法替代。
基於短語的 SMT
這種方法基於所有基於詞的翻譯原則:統計、重新排序和詞法分析。但是,在學習時,它不僅會將文本分成詞,還會分成短語。確切地說,這些是 n-gram,即 n 個詞連在一起構成的連續序列。
因此,這個機器能學習翻譯穩定的詞組合,這能顯著提升準確度。

其中的訣竅在於,這裡的短語並不總是簡單的句法結構,而且如果有人明白語言學並乾預了其中的句子結構,那麽翻譯的品質就會大幅下降。計算語言學先驅 Frederick Jelinek 曾經開玩笑地說:「每次我炒掉一個語言學家,語音識別器的表現就會上升一點。」
除了提升準確度,基於短語的翻譯在選擇所要學習的雙語文本上提供了更多選擇。對於基於詞的翻譯,源文本之間的準確匹配是至關重要的,這就排除了讓任何文學翻譯或自由翻譯。基於短語的翻譯則可以從中學習。為了提升翻譯品質,研究者甚至開始解析不同語言的新聞網站。

自 2006 年以來,每個人都開始使用這種方法。谷歌翻譯、Yandex、必應等一些著名的在線翻譯工具將基於短語的方法用到了 2016 年。你們可能都還記得谷歌要麽得到毫無差錯的翻譯句子,要麽得到毫無意義的結果的時候吧?這種毫無意義就來自基於短語的功能。
老一輩基於規則的方法總是會得到可預測的但也很糟糕的結果。統計方法則總是會得到出人意料和讓人困惑的結果。谷歌翻譯會毫不猶豫地將「three hundred」變成「300」。這就是所謂的統計異常(statistical anomaly)。
基於短語的翻譯已經變得非常流行,當你聽到人們說「統計機器翻譯」時,多半就是指它。在 2016 年之前,所有的研究都稱讚基於短語的翻譯是表現最好的。那時候,甚至沒人認為谷歌已經在燃起戰火,準備改變整個機器翻譯圖景了。
基於句法的 SMT
這種方法應當被簡要提及一下。在神經網絡出現的很多年前,基於句法的翻譯被認為是「翻譯的未來」,但這一思想並未迎來騰飛。
基於句法的翻譯的支持者相信它有可能與基於規則的方法融合。它需要對句子進行相當準確的句法分析——以確定主語、謂語和句子的其它部分,然後再構建一個句子樹。機器可以使用它來學習轉換語言之間的句法單元並根據詞或短語來翻譯其余部分。那應該可以一勞永逸地解決詞對齊問題。

來自 Yamada and Knight [2001] 的示例(http://www.aclweb.org/anthology/P01-1067)以及這個很棒的幻燈片(http://homepages.inf.ed.ac.uk/pkoehn/publications/esslli-slides-day5.pdf)
問題是句法分析的效果很差,儘管事實上我們認為這在之前已經得到了解決(因為我們有很多語言的現成可用的庫)。我曾經試過使用句法樹來解決比單純地解析主語和謂語更複雜的任務。但我每次都放棄了,然後使用了另一種方法。
如果你成功過至少一次,請讓我知道。
神經機器翻譯(NMT)
2014 年,一篇關於將神經網絡用於機器翻譯的出色論文發布:https://arxiv.org/abs/1406.1078。互聯網並沒關注這項研究,但谷歌除外——他們挽起袖子就幹了起來。兩年之後的 2016 年 9 月,谷歌發布了改變機器翻譯領域的公告,參閱《重磅 | 谷歌翻譯整合神經網絡:機器翻譯實現顛覆性突破》。
這一思想接近照片之間的風格遷移。知道 Prisma 這樣的應用嗎?它能用某幅著名藝術作品的風格來渲染圖片。但這不是魔法。是神經網絡學會了識別藝術家的畫作。接下來,包含網絡決策的最後一層被移除了。所得到的風格化影像只是網絡所得到的中間影像。這是網絡自己的幻想,而我們覺得這很美。

如果我們可以遷移照片的風格,那我們能不能將另一種語言施加到源文本上呢?我們可以將文本看作是帶有某種「藝術家風格」,我們希望在遷移這個風格的同時又保證這些文本的本質不變。
想象一下,假如我要描述我的狗——平均個頭、尖鼻子、短尾巴、老是叫喚。如果我把這些狗的特徵給你並且描述是準確的,你就可以畫出它,即使你從沒見過它。

現在,再想象源文本是特定特徵的集合。基本上而言,這意味著你可以編碼它,然後再讓其它神經網絡將其解碼回文本——但是另一種語言的文本。解碼器只知道自己的語言。它對這些特徵的來源一無所知,但它可以用西班牙語等語言將其表達出來。再繼續前面的比喻,不管你是怎麽畫這條狗的(用蠟筆、水彩或你的手指),你都可以把它畫出來。
再說明一次:一個神經網絡只能將句子編碼成特定的特徵集合,另一個神經網絡只能將其解碼成文本。這兩者彼此都不知情,而且都隻各自了解自己的語言。想起什麽沒有?「中間語言」回來了!

問題是,我們如何找到這些特徵?對於狗來說,特徵當然很明顯,但文本的特徵是怎樣的?三十年前科學家就已經在嘗試創建通用語言代碼了,但最終以失敗告終。
儘管如此,我們現在有深度學習了。尋找特徵是它的基本任務!深度學習和經典神經網絡之間的主要區別是搜索這些特定特徵的能力,而無需對這些特徵的本質有任何了解。如果神經網絡足夠大,而且有數千塊顯卡可用,那就能很好地找到文本中的這些特徵。
理論上講,我們可以將這些神經網絡得到的特徵交給語言學家,這樣他們就可以為自己打開一片新視野了。
但問題是編碼和解碼應該使用哪種類型的神經網絡呢?卷積神經網絡(CNN)完美適用於影像,因為它們可以操作獨立的像素塊。
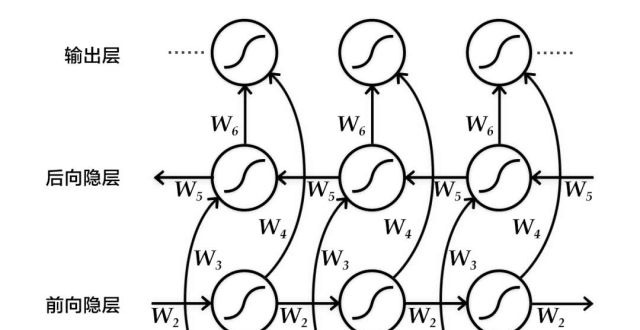
但文本中沒有獨立的塊——每個詞都取決於自己的語境。文本、語音、音樂都是連續的。所以循環神經網絡(RNN)是處理它們的最佳選擇,因為它們能記住之前的結果——在這裡即是之前的詞。
現在很多應用都已經使用了 RNN,包括 Siri 的語音識別(解析聲音序列,其中後一個聲音取決於前一個聲音)、鍵盤提示(記住之前的經歷,猜測下一個詞)、音樂生成和聊天機器人。

致像我一樣的技術宅:事實上,神經翻譯器的架構非常多樣。一開始是用的常規 RNN,後來更新成了雙向 RNN,其中翻譯器不僅要考慮源詞之前的詞,還有考慮其後的詞。這要高效得多。然後它又使用了帶有 LSTM 單元的多層 RNN,可以實現翻譯語境的長期存儲。
短短兩年時間,神經網絡在翻譯上的表現就超越了過去 20 年來的一切。神經翻譯的詞序錯誤少了 50%、詞匯錯誤減少了 17%、語法錯誤減少了 19%。神經網絡甚至學會了協調不同語言的性和格。而且並沒有人教它們這樣做。
這一領域最值得提及的進展是從沒使用過直接翻譯。統計機器翻譯方法總是可以使用英語作為關鍵源。因此,如果你要將俄語翻譯成德語,機器會首先將俄語翻譯成英語,然後再將英語翻譯成德語,這會造成雙倍損失。
神經翻譯無需這樣做——只需要一個解碼器就行了。沒有共同詞典的語言之間也能實現直接翻譯,這是有史以來的第一次。

谷歌翻譯(自 2016 年以來)
2016 年,谷歌為 9 種語言啟用了神經翻譯。他們開發出了名為谷歌神經機器翻譯(GNMT)的系統。它由 8 個編碼器和 8 個解碼器 RNN 層構成,另外還有來自解碼器網絡的注意連接。
他們不僅會切分句子,而且還會切分詞。這正是他們解決 NMT 一大主要難題的方法——即罕見詞問題。但出現了它們詞匯庫中沒有的詞時,NMT 是無能為力的。比如說「Vas3k」。我估計沒人讓神經網絡學習翻譯我的昵稱。在遇到罕見詞時,GNMT 會嘗試將詞分解成詞片段,然後根據這些片段得到翻譯結果。很聰明的做法。

提示:瀏覽器中用於網站翻譯的谷歌翻譯仍然用的是老舊的基於短語的算法。不知為何谷歌沒有更新,而且其翻譯結果和在線版本谷歌翻譯相比差距其實相當大。
在線版本的谷歌翻譯使用了眾包機制。人們可以選擇他們認為最正確的版本,而且如果很多用戶都認同,那麽谷歌就會一直按這種方式翻譯這個短語並將其標注為一個特例。對於「Let』s go to the cinema」或「I』m waiting for you」等日常使用的短句而言,這種做法效果很好。谷歌的英語會話水準比我還好,不開森~
微軟必應的工作方式和谷歌翻譯差不多。但 Yandex 不一樣。
Yandex Translate(自 2017 年以來)
Yandex 於 2017 年推出了自己的神經翻譯系統。該公司宣稱其主要特色是混合性(hybridity)。Yandex 將神經方法和統計方法組合到了一起來執行翻譯,然後再使用其最喜歡的 CatBoost 算法從中選出最好的一個。
問題是神經翻譯在翻譯短句時常常出錯,因為它需要使用上下文來選擇正確的詞。如果一個詞在訓練數據中出現的次數非常少,那就很難得到正確的結果。在這種情況下,簡單的統計翻譯能輕鬆快捷地找到正確的詞。

在句子末尾加上句號後,Yandex 的翻譯結果更好了,因為這時候它啟用了神經網絡機器翻譯。
Yandex 沒有分享具體的技術細節。它用行銷新聞稿搪塞了我們。好吧。
看起來谷歌使用了 SMT 來執行詞和短句的翻譯。他們沒有在任何文章中提及這一點,但如果你查看短表達和長表達之間的差別,你就能相當明顯地注意到。此外,SMT 也被用來展示詞的統計情況。
結論和未來
每個人都仍然為「巴別魚」(即時語音翻譯)的構想感到興奮。谷歌已經帶著 Pixel Buds 耳機向這個方向邁出了一步,但事實上這仍然達不到我們夢想的效果。即時語音翻譯與通常的翻譯不同。系統需要知道何時開始翻譯以及何時閉嘴聆聽。我還沒見到過任何能夠解決這一問題的方法。也許,Skype 還行吧……
而且有待推進的領域不止這一個:所有的學習都受限於並列文本塊的集合。最深度的神經網絡仍然是在並列文本中學習。如果不向神經網絡提供資源,它就無法學習。而人類可以通過閱讀書籍和文章來擴增自己的詞匯庫,即使不會將其翻譯成自己的母語。
如果人類能做到,神經網絡就也能做到。理論上講是這樣。我隻發現了一個原型設計試圖開發出能讓知曉一種語言的網絡能通過閱讀另一種語言的文本來獲取經驗:https://arxiv.org/abs/1710.04087。我倒是想自己試試看,但我很笨。好了,就這樣吧。
有用的鏈接
Philipp Koehn:統計機器翻譯:https://www.amazon.com/dp/0521874157/。我發現方法的最完整的集合。
Moses:http://www.statmt.org/moses/。一個很受歡迎的庫,可用於創建自己的統計翻譯系統。
OpenNMT:http://opennmt.net/。另一個庫,但是用來創建神經翻譯器的
我最喜歡的博主的文章,解釋了 RNN 和 LSTM:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
影片「如何製作一個語言翻譯器」:https://youtu.be/nRBnh4qbPHI。這家夥很有趣,解釋得很不錯,但不夠充分。
來自 TensorFlow 的文本教程,教你如何創建神經翻譯器:https://www.tensorflow.org/tutorials/seq2seq。想查看更多案例和嘗試代碼的人可以參考。