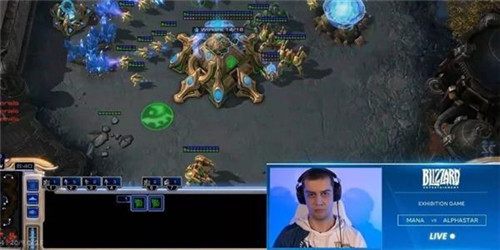
騰訊科技訊 據國外媒體報導,日前,谷歌(Google)旗下DeepMind公司開發的人工智能軟體玩家在“星海爭霸II”(Starcraft II)遊戲中上擊敗了人類玩家——這在人工智能領域尚屬首例。
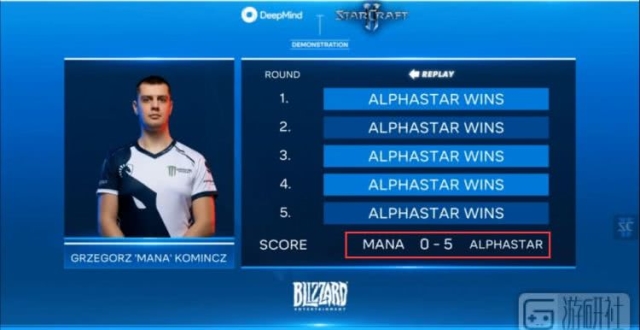
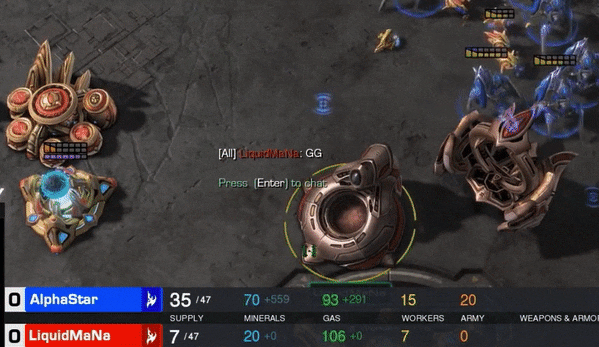
在YouTube和Twitch上播放的一系列遊戲比賽中,AI玩家連續10場擊敗人類玩家。在最後一場比賽中,職業遊戲玩家科明茨(Grzegorz “MaNa” Komincz)為人類奪取了一場勝利。
DeepMind公司的研究負責人大衛·西爾弗(David Silver)在比賽結束後表示:“人工智能在不同的遊戲比賽中取得的成績,成為人工智能發展的重要里程碑。我希望——儘管顯然還有工作要做——未來的人們可能會回顧今天,並認識到這是人工智能系統潛在能力又邁出的重要一步。”
在電子遊戲中打敗人類看起來像是人工智能發展中的一場雜耍,但這其實是一個重大的研究挑戰。像“星海爭霸2”這樣的遊戲比棋類遊戲(如國際象棋或圍棋)更難玩。在電子遊戲中,人工智能軟體實體不能通過觀察每一個棋子的運動來計算下一步的動作,他們必須實時作出反應。

這些因素看起來並不是DeepMind人工智能遊戲玩家系統(AlphaStar)的主要障礙。首先,它擊敗了職業玩家達裡奧“TLO”Wünsch,然後它開始挑戰科明茨。一系列比賽最初於去年12月在DeepMind的倫敦總部舉行,但今天對科明茨的最後一場比賽提供了直播,這位職業玩家為人類帶來了一場勝利。
專業的星海爭霸評論員形容AlphaStar的表現是“非凡的”和“超人的”。
在“星海爭霸II”中,首先需要從同一張地圖的不同位置開始,隨後建立基地、訓練軍隊和入侵敵人領土。AlphaStar特別擅長所謂的“微管理”(Micromanagement),即在戰場上快速果斷地控制部隊的能力。
儘管人類玩家有時能訓練出更強大的軍隊,但AlphaZero仍能在近距離擊敗他們。在一場遊戲中,AlphaStar用一個快速移動的“潛行者”(Stalker)聚集了法力。評論員凱文“鹿特丹”范德科形容它實現了“非凡的軍隊控制,這不是一般人平時所能看到的水準。”
在遊戲比賽結束之後,科明茨表示:“如果我和任何人類對手比賽,他們就不會以這麽高的水準對‘潛行者’進行微操控。”
這一事件與我們從其他高級人工智能遊戲玩家中看到的行為相呼應。
去年,當OpenAI公司的AI玩家參加Dota 2的比賽時,他們最終被人類玩家所擊敗。不過,當時業內專家點評指出,AI軟體玩家表現出了優秀的清晰度和準確度,能夠快速無誤地做出判斷,這也是人工智能玩家的優勢所在。
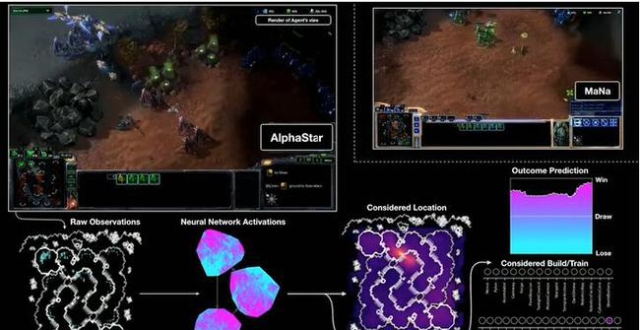
專家們已經開始剖析這一次的遊戲對決,並討論AlphaStar是否獲得了任何不公平的優勢。人工智能玩家(軟體實體)在某些方面表現不佳,例如,AI玩家每分鐘進行的點擊次數被限制。不過,與人類玩家不同的是,它能夠一次查看整個地圖,而不是手動導航。
DeepMind公司的研究人員說,AI玩家實際上並未獲得真正的優勢,因為它在任何時候隻專注於地圖的一個部分。但是,正如遊戲過程所顯示,這並沒有阻止AlphaStar同時在三個不同的區域熟練地控制部隊。評論員表示,這對人類玩家來說是不可能的。值得注意的是,當科明茨在直播的比賽中擊敗AlphaStar時,AI正在使用一個受限的相機視圖模式。
另外需要指出的是,這次和人工智能玩家對決的對手雖然是職業玩家,但並不是世界冠軍水準。參加比賽的玩家TLO還必須完成星海爭霸II中他所不熟悉的比賽。

撇開這一討論不談,專家們說,這場比賽是人工智能向前邁出的重要一步。長期參與“星海爭霸”人工智能場景研究的研究員戴夫·丘吉爾告訴英國“衛報”:“我認為人工智能遊戲軟體實體所表現出的能力是一項重大成就,至少比我在人工智能研究人員中聽到的最樂觀的猜測早一年。”
然而,丘吉爾也補充說,由於DeepMind還沒有發布任何有關這項工作的研究論文,因此很難判斷出AlphaStar是否獲得了任何技術上的飛躍。丘吉爾說:“我還沒有讀過這篇部落格文章,也沒有看到任何檔案或技術細節來做出一個判斷。”
佐治亞理工學院人工智能副教授馬克·裡德爾(Mark Riedl)說,他對遊戲比賽結果並不感到驚訝,人工智能擊敗人類玩家只是“一個時間問題”。
裡德爾補充說,他並不認為這場比賽表明星海爭霸II確實被人工智能玩家所征服。他表示,在過去直播的遊戲中,AlphaStar被限制在視窗中,這消除了人工智能的一些優勢,“但我們看到的更大問題…是人工智能所學到的策略是脆弱的,當一個職業玩家把人工智玩家逼出舒適區時,人工智能就會崩潰。”
實際上,讓人工智能玩家在電子遊戲中擊敗人類,其最終目的是提高人工智能的訓練方法,特別是創造出能夠在類似星海爭霸這樣複雜的虛擬環境中運行的人工智能系統。
為了訓練AlphaStar,DeepMind公司的研究人員使用了一種稱為強化學習的方法。AI軟體實體為了達到某些目標(如獲勝或僅僅是活著),基本上是通過反覆試驗來玩這個遊戲的。他們首先通過模仿人類玩家來學習,然後在遊戲競技比賽中互相學習。在不同的AI軟體實體中,強者生存,弱者被拋棄。DeepMind估計,它的每一個AlphaStar軟體實體都以這種方式積累了大約200年的遊戲時間,隨著遊戲積累,它們玩遊戲的速度也越來越快。
DeepMind清楚地知曉其開展這項工作的目標。“最重要的是,DeepMind的任務是構建一種通用的人工智能系統。”AlphaStar項目的負責人奧裡爾·維尼亞爾斯(Oriol Vinyals)說,他指的是建立一個能執行人類所能完成的任何心理任務的人工智能軟體實體。“要做到這一點,重要的是要對我們的人工智能軟體實體在各種任務中的表現進行測評對比。”(騰訊科技審校/承曦)