曉查 發自 凹非寺
量子位 報導 | 公眾號 QbitAI
“我在網上看到過很多神經網絡的實現方法,但這一篇是最簡單、最清晰的。”
一位來自普林斯頓的華人小哥Victor Zhou,寫了篇神經網絡入門教程,在線代碼網站Repl.it聯合創始人Amjad Masad看完以後,給予如是評價。
這篇教程發布僅天時間,就在Hacker News論壇上收獲了574讚。程序員們紛紛誇讚這篇文章的代碼寫得很好,變量名很規範,讓人一目了然。
下面就讓我們一起從零開始學習神經網絡吧。
實現方法
搭建基本模塊——神經元
在說神經網絡之前,我們討論一下神經元(Neurons),它是神經網絡的基本單元。神經元先獲得輸入,然後執行某些數學運算後,再產生一個輸出。比如一個2輸入神經元的例子:

在這個神經元中,輸入總共經歷了3步數學運算,
先將兩個輸入乘以權重(weight):
x1x1×w1
x2x2×w2
把兩個結果想加,再加上一個偏置(bias):
(x1×w1)+(x2×w2)+ b
最後將它們經過激活函數(activation function)處理得到輸出:
y = f(x1×w1+x2×w2+ b)
激活函數的作用是將無限制的輸入轉換為可預測形式的輸出。一種常用的激活函數是sigmoid函數:

sigmoid函數的輸出介於0和1,我們可以理解為它把 (?∞,+∞) 範圍內的數壓縮到 (0, 1)以內。正值越大輸出越接近1,負向數值越大輸出越接近0。
舉個例子,上面神經元裡的權重和偏置取如下數值:
w=[0,1]
b = 4
w=[0,1]是w1=0、w2=1的向量形式寫法。給神經元一個輸入x=[2,3],可以用向量點積的形式把神經元的輸出計算出來:
w·x+b =(x1×w1)+(x2×w2)+ b= 0×2+1×3+4=7
y=f(w?X+b)=f(7)=0.999
以上步驟的Python代碼是:
我們在代碼中調用了一個強大的Python數學函數庫NumPy。
搭建神經網絡
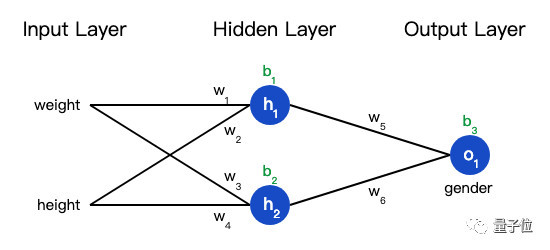
神經網絡就是把一堆神經元連接在一起,下面是一個神經網絡的簡單舉例:

這個網絡有2個輸入、一個包含2個神經元的隱藏層(h1和h2)、包含1個神經元的輸出層o1。
隱藏層是夾在輸入輸入層和輸出層之間的部分,一個神經網絡可以有多個隱藏層。
把神經元的輸入向前傳遞獲得輸出的過程稱為前饋(feedforward)。
我們假設上面的網絡裡所有神經元都具有相同的權重w=[0,1]和偏置b=0,激活函數都是sigmoid,那麽我們會得到什麽輸出呢?
h1=h2=f(w?x+b)=f((0×2)+(1×3)+0)
=f(3)
=0.9526
o1=f(w?[h1,h2]+b)=f((0?h1)+(1?h2)+0)
=f(0.9526)
=0.7216
以下是實現代碼:
訓練神經網絡
現在我們已經學會了如何搭建神經網絡,現在我們來學習如何訓練它,其實這就是一個優化的過程。
假設有一個數據集,包含4個人的身高、體重和性別:
現在我們的目標是訓練一個網絡,根據體重和身高來推測某人的性別。

為了簡便起見,我們將每個人的身高、體重減去一個固定數值,把性別男定義為1、性別女定義為0。
在訓練神經網絡之前,我們需要有一個標準定義它到底好不好,以便我們進行改進,這就是損失(loss)。
比如用均方誤差(MSE)來定義損失:
n是樣本的數量,在上面的數據集中是4;
y代表人的性別,男性是1,女性是0;
ytrue是變量的真實值,ypred是變量的預測值。
顧名思義,均方誤差就是所有數據方差的平均值,我們不妨就把它定義為損失函數。預測結果越好,損失就越低,訓練神經網絡就是將損失最小化。
如果上面網絡的輸出一直是0,也就是預測所有人都是男性,那麽損失是:
MSE= 1/4 (1+0+0+1)= 0.5
計算損失函數的代碼如下:
減少神經網絡損失
這個神經網絡不夠好,還要不斷優化,盡量減少損失。我們知道,改變網絡的權重和偏置可以影響預測值,但我們應該怎麽做呢?
為了簡單起見,我們把數據集縮減到隻包含Alice一個人的數據。於是損失函數就剩下Alice一個人的方差:
預測值是由一系列網絡權重和偏置計算出來的:
所以損失函數實際上是包含多個權重、偏置的多元函數:
(注意!前方高能!需要你有一些基本的多元函數微分知識,比如偏導數、鏈式求導法則。)
如果調整一下w1,損失函數是會變大還是變小?我們需要知道偏導數?L/?w1是正是負才能回答這個問題。
根據鏈式求導法則:
而L=(1-ypred)2,可以求得第一項偏導數:
接下來我們要想辦法獲得ypred和w1的關係,我們已經知道神經元h1、h2和o1的數學運算規則:
實際上只有神經元h1中包含權重w1,所以我們再次運用鏈式求導法則:
然後求?h1/?w1
我們在上面的計算中遇到了2次激活函數sigmoid的導數f′(x),sigmoid函數的導數很容易求得:
總的鏈式求導公式:
這種向後計算偏導數的系統稱為反向傳播(backpropagation)。
上面的數學符號太多,下面我們帶入實際數值來計算一下。h1、h2和o1
h1=f(x1?w1+x2?w2+b1)=0.0474
h2=f(w3?x3+w4?x4+b2)=0.0474
o1=f(w5?h1+w6?h2+b3)=f(0.0474+0.0474+0)=f(0.0948)=0.524
神經網絡的輸出y=0.524,沒有顯示出強烈的是男(1)是女(0)的證據。現在的預測效果還很不好。
我們再計算一下當前網絡的偏導數?L/?w1:

這個結果告訴我們:如果增大w1,損失函數L會有一個非常小的增長。
隨機梯度下降
下面將使用一種稱為隨機梯度下降(SGD)的優化算法,來訓練網絡。
經過前面的運算,我們已經有了訓練神經網絡所有數據。但是該如何操作?SGD定義了改變權重和偏置的方法:
η是一個常數,稱為學習率(learning rate),它決定了我們訓練網絡速率的快慢。將w1減去η·?L/?w1,就等到了新的權重w1。
當?L/?w1是正數時,w1會變小;當?L/?w1是負數 時,w1會變大。
如果我們用這種方法去逐步改變網絡的權重w和偏置b,損失函數會緩慢地降低,從而改進我們的神經網絡。
訓練流程如下:
1、從數據集中選擇一個樣本;
2、計算損失函數對所有權重和偏置的偏導數;
3、使用更新公式更新每個權重和偏置;
4、回到第1步。
我們用Python代碼實現這個過程:
隨著學習過程的進行,損失函數逐漸減小。

現在我們可以用它來推測出每個人的性別了:
更多
這篇教程只是萬裡長征第一步,後面還有很多知識需要學習:
1、用更大更好的機器學習庫搭建神經網絡,如Tensorflow、Keras、PyTorch
2、在瀏覽器中的直觀理解神經網絡:https://playground.tensorflow.org/
3、學習sigmoid以外的其他激活函數:https://keras.io/activations/
4、學習SGD以外的其他優化器:https://keras.io/optimizers/
5、學習卷積神經網絡(CNN)
6、學習遞歸神經網絡(RNN)
這些都是Victor給自己挖的“坑”。他表示自己未來“可能”會寫這些主題內容,希望他能陸續把這些坑填完。如果你想入門神經網絡,不妨去訂閱他的部落格。
關於這位小哥
Victor Zhou是普林斯頓2019級CS畢業生,已經拿到Facebook軟體工程師的offer,今年8月入職。他曾經做過JS編譯器,還做過兩款頁遊,一個仇恨攻擊言論的識別庫。
最後附上小哥的部落格鏈接:
https://victorzhou.com/
—完—
訂閱AI內參,獲取行業資訊
誠摯招聘
量子位正在招募編輯/記者,工作地點在北京中關村。期待有才氣、有熱情的同學加入我們!相關細節,請在量子位公眾號(QbitAI)對話界面,回復“招聘”兩個字。
喜歡就點「好看」吧 !