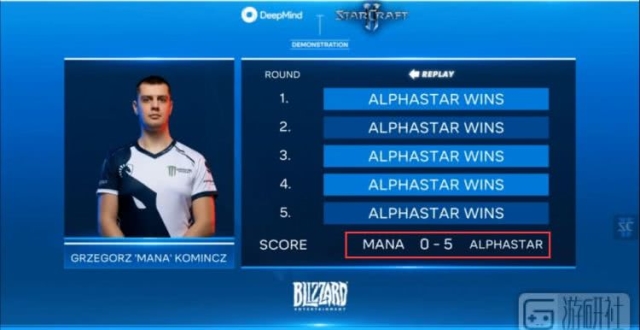
剛剛,我們見證了 AI 與人類 PK 的又一次重大進展!DeepMind 台灣時間 1 月 25 日凌晨 2:00 起公布了其錄製的 AI 在《星海爭霸 2》中與2位職業選手的比賽過程:AlphaStar 5:0 戰勝職業選手TLO ,5:0戰勝 2018 年 WSC 奧斯汀站亞軍 MaNa 。與兩位人類對手的比賽相隔約兩周,AI 自學成才,經歷了從與TLO 對戰時的菜鳥級別,進化到完美操作的過程,尤其是與MaNa 的對戰,已經初步顯示了可以超越人類極限的能力。
這次的演示也是 DeepMind 的星海爭霸 2 AI AlphaStar 的首次公開亮相。除了此前比賽錄像的展示外,AlphaStar 還和MaNa 現場來了一局,不過,這局AlphaStar 輸給了人類選手MaNa 。

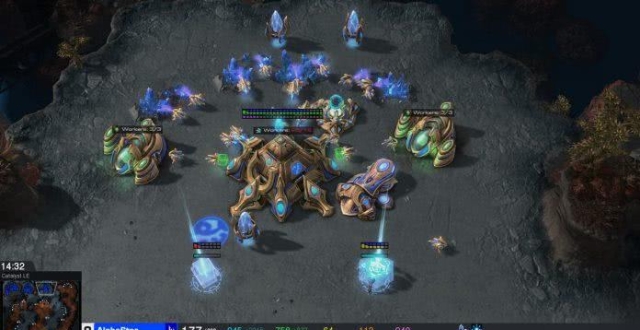
圖 | MaNa 正在聚精會神比賽(圖源:Youtube)
DeepMind 在演示中介紹,雙方的比賽固定在 Catalyst LE 地圖,採用 4.6.2 遊戲版本,而且只能進行神族內戰,雙方將進行 5 場比賽。首先接受邀請的是 Liquid 戰隊的蟲族選手 TLO,目前世界排名 68。

第一場比賽,TLO 出現在 10 點鍾方向,AlphaStar 出現在 4 點鍾對角方向。TLO 的開場非常傳統,採用了雙兵營封路的開局,但 AlphaStar 並沒有封路,這一問題被 TLO 的農民偵查到,他果斷拍出使徒,採用了常見的殺農民騷擾策略。
雖然 AlphaStar 沒有封路,直接放進了 TLO 的使徒,但 AlphaStar 的雙兵營也造出了使徒防守,導致 TLO 的第一次騷擾隻殺掉了兩個農民,剩下的使徒也無功而返。
隨後雙方都開始補出追獵,TLO 開始用先知騷擾。雙方進行了多個小規模交戰,幾波互換幾乎平手,AlphaStar 損失的農民較多,TLO 損失了多個使徒。在交戰中,我們看到了 AlphaStar 進行了類似人類的微操,一邊撤退,一邊反打 TLO 的追獵,同時利用棱鏡傳輸兵力。

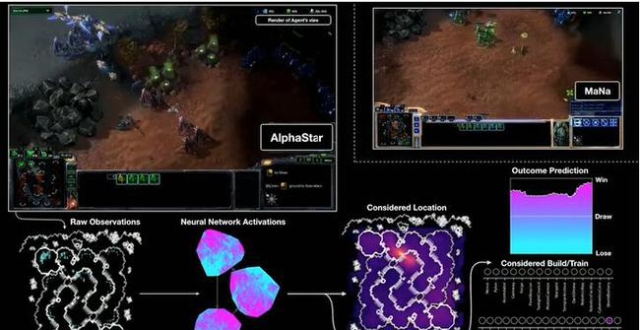
圖 | AlphaStar 的視野,它可以看到全地圖戰爭迷霧之外發生了什麽,然後做出決策,實現全局資源調度(圖源:Youtube)
不過 TLO 此時的二礦剛剛建好,AlphaStar 只有單礦,將更多的經濟轉化成了兵力,因此 AlphaStar 爆出了更多的追獵,直接選擇進攻二礦,TLO 的追獵寡不敵眾,在主力兵力被殲滅後打出 GG。
第一局以 DeepMind 的勝出為結果,我們看到了 AlphaStar 的一些不同尋常做法,比如不選擇互相騷擾農民,而是直接用兵力防守,然後發現 TLO 拍下二礦之後,在正面戰場用一定數量的追獵持續壓製。
由於時間限制,演示中並沒有播放所有比賽,而是在展示了另外一局比賽錄像後,給出了 TLO 五局全敗的戰績。不過所有的錄像都將在 DeepMind 官網上放出,供人下載。
TLO 在演示中表示,他覺得自己還是可以贏的,如果能夠有更多的訓練時間,對 AlphaStar 有更多的了解,是一定可以找到 AlphaStar 弱點,然後獲勝的。
隨後登場的是 Liquid 戰隊 MaNa,作為排名 19 的神族選手,他比 TLO 更加強大。如果 AlphaStar 可以戰勝他,那將說明 AlphaStar 真的具備了人類頂尖選手的實力。

圖 | AlphaStar 和人類選手的 APM 並沒有太大區別(圖源:Youtube)
與 MaNa 的第一局,雙方都是“常規”開局,MaNa 封路,AlphaStar 沒有封路。不過 AlphaStar 采取了變種戰略,選擇在 MaNa 基地附近放下水晶,拍下兩個兵營,準備利用兵營距離的優勢進攻。MaNa 此時還在按照人類的思路,利用使徒騷擾農民。
在 AlphaStar 兵營快完成的時候,被 MaNa 發現,他果斷采取了防守措施,在高坡建造了兩個充電站,準備利用封路和高坡的優勢防守即將到來的追獵大軍。按照 MaNa 的想法,“正常的人類選手是不會走上那個高坡的”。
但是 AlphaStar 並不是人類,它猶豫兩次之後選擇直接攻上高地,由於追獵數量碾壓 MaNa,野兵營還在源源不斷地輸出追獵,因此充電站幾乎沒有效果,幾輪點射之後,MaNa 的追獵所剩無幾,最終拉出所有農民也沒能挽回敗局,宣告失敗。
在隨後的兩局錄像複盤中,我們看到了 AlphaStar 的強大微操和戰術思路,它會學習和嘗試人類的封路戰術,生產額外的農民緩解騷擾帶來的影響。在一局比賽中,我們看到了 AlphaStar 使用了純追獵戰術,僅靠強大的微操對抗 MaNa 的追獵、不朽和叉子組合的混合軍隊。

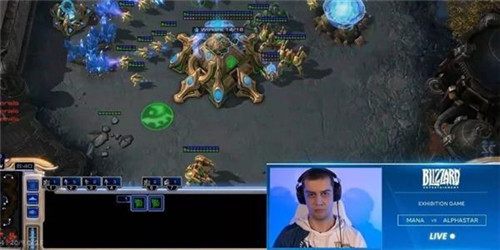
圖 | 實時戰局(圖源:Youtube)
AlphaStar 將 30 多個追獵分成 2-3 組,從 3 個方向包夾 MaNa 的進攻部隊,然後靠閃爍躲避 9 個不朽的攻擊,這種非人類的操作徹底摧毀了 MaNa 的操作空間——無論他建造多少個不朽,都沒有辦法抵抗追獵大軍。“這種情況在同水準人類對局中完全不會出現,”MaNa 在演講中無奈地說道。
最終 MaNa 也以 0-5 的成績敗北,人類與 AlphaStar 的 10 局比賽結果全是失敗。
不過在演示直播中,DeepMind 似乎有些膨脹,選擇與 MaNa 進行了一場即時表演賽,後者也表示,自己要為 Liquid 戰隊正名,捍衛戰隊和人類的榮譽。
雙方常規開局,在前期並沒有進行大規模交戰。但 MaNa 顯然是有備而來,沒有使用使徒和先知騷擾,而是專注於偵查和攀升科技。在發現 AlphaStar 依舊生產了茫茫多追獵後,MaNa 採用了棱鏡運輸不朽的騷擾戰術,同時補出不朽、叉子和執政官等混合部隊。這可謂是整場比賽的神來之筆。

圖 | 三個先知圍著棱鏡看熱鬧(圖源:Youtube)
在空投不朽騷擾農民時,AlphaStar 並沒有選擇補出鳳凰打擊棱鏡,而是用不能攻擊空中部門的先知跟蹤棱鏡,輔以數十個追獵來回往返前線和家中。看起來,它認為追獵可以對空攻擊,因此不需要補出鳳凰,而且似乎所有追獵都在一個分組內,沒有分批分別執行進攻和防守任務。
於是我們看到了人類玩家對抗 AI 的典型方法:逼迫後者陷入循環執行某種任務的怪圈,使其浪費巨額時間和資源,無法形成有效的局勢判斷。
就這樣,MaNa 消耗到了自己的兵力成型,然後一波壓製直接瓦解了 AlphaStar 的純追獵部隊。後者還嘗試利用包夾的戰術阻擋 MaNa,但這一次 MaNa 的兵力充足,不朽對追獵的克制十分明顯,沒有留給 AlphaStar 一絲操作的機會,全殲對手,獲得了寶貴的勝利。

圖 | MaNa 獲得表演賽勝利,露出了迷之微笑(圖源:Youtube)
雖然 TLO 和 MaNa 的錄像以全敗告終,宣告了 DeepMind AlphaStar 的實力已經不可同日而語,但這場表演賽充分暴露了 AlphaStar 目前的不足。
我們不難看出,儘管其神經網絡已經趨於長期優化,但似乎仍然會在一定程度上陷入局部最優,被人類發現固定模式,落入圈套,而且從 5 個小叮當抱團,到純追獵部隊,都顯示出它對遊戲兵種的理解尚不到位,如果最後一局它可以像人類一樣直接派出鳳凰防守棱鏡,或許它將繼續憑借超強的微操一波推平 MaNa。
比賽回放過程中,主持人問到 DeepMind 科學家,平時如何訓練 AlphaStar,DeepMind 科學家 Oriol Vinyals、David Silver 表示,首先是模仿學習,團隊從許多選手那裡獲得了很多比賽回放資料,並試圖讓 AI 通過觀察一個人所處的環境,盡可能地模仿某個特定的動作,從而理解星海爭霸的基本知識。這其中所使用到的訓練資料不但包括專業選手,也包括業餘選手。這是 AlphaStar 成型的第一步。

圖 | DeepMind 科學家 Oriol Vinyals(圖源:Youtube)

圖 | DeepMind 科學家 David Silver(圖源:Youtube)
之後,團隊會使用一個稱為“Alpha League”的方法。在這個方法中,Alpha League 的第一個競爭對手就是從人類數據中訓練出來的神經網絡,然後進行一次又一次的迭代,產生新的 agent 和分支,用以壯大“Alpha League”。

圖 | Alpha League 示意圖(圖源:Youtube)
然後,這些 agent 通過強化學習過程與“Alpha League”中的其他競爭對手進行比賽,以便盡可能有效地擊敗所有這些不同的策略,此外,還可以通過調整它們的個人學習目標來鼓勵競爭對手朝著特定方式演進,比如說旨在獲得特定的獎勵。
最後,團隊在“Alpha League”中選擇了最不容易被利用的 agent,稱之為“the nash of League”,這就是 TLO 所對戰的5個。
為什麽是"星海爭霸 2"?
比賽前期,DeepMind 與暴雪就聯合發布了關於此次比賽的重磅預告:將在台灣時間周五凌晨 2 點展示 Deepmind 研發的 AI 在即時戰略遊戲星海爭霸 2 上的最新進展。如今,這個進展終於揭開神秘面紗。
而 DeepMind 開發星海爭霸 2 AI,最早可以追溯到 2016 年。當時,DeepMind 研究科學家 Oriol Vinyals 在暴雪嘉年華現場透露 Deepmind 與星海爭霸 2 緊密合作的最新進展及未來的計劃。在 AlphaGo 在 2017 年圍棋大獲全勝之後,DeepMind 開始對外宣布,團隊正在著手讓人工智能征服星海爭霸 2,這款遊戲對人工智能在處理複雜任務上的成功提出了"重大挑戰"。
在 2018 年 1 月的 EmTech 大會上,谷歌 DeepMind 科學家 Oriol Vinyals 曾對 DT 君表示,第一版的 AlphaGo 擊敗了樊麾,後來下一個版本在韓國和李世石進行了對弈並取得了勝利。再後來進一步地訓練網絡,整個網絡比之前強了三倍,贏了柯潔和其他專業棋手。團隊是從零開始,一點點積累積數據訓練,最後戰勝了專業棋手。而除了棋類遊戲以外,DeepMind 比較感興趣的,就是遊戲星海爭霸 2。
繼圍棋之後,DeepMind 為什麽要選擇星海爭霸 2 這款遊戲為下一個目標呢?
星海爭霸 2 是由美國著名遊戲公司暴雪娛樂(Blizzard Entertainment)推出的一款以星際戰爭為題材的即時戰略遊戲。星海爭霸 2 具備策略性、競爭性的特性,在全球都非常火爆,並且每年都會舉辦大量的比賽,因此也有著海量的玩家基礎。

圖丨谷歌 DeepMind 科學家 Oriol Vinyals(來源:DeepTech)
據 Oriol Vinyals 當時透露,星海爭霸 2 是非常有趣和複雜的遊戲,這個遊戲基本上是建造一些建築物以及部門,在同一個地圖裡不同的組織會相互競爭。在這個遊戲中,哪怕只是建造建築物,也需要做出許多決策。除此之外,還要不斷收集和利用資源、建造不同的建築物、不斷擴張,因此整個遊戲非常具有挑戰性。
而且,和圍棋任務最大的不同在於,圍棋可以看到整個棋盤,但是在星海爭霸 2 中我們通常無法看到整個地圖,需要派小兵出去偵查。另外,遊戲是不間斷進行的。整個遊戲甚至會有超過 5000 步的操作。對於增強學習這種方法來說,除了上下左右這些普通的移動,用滑鼠點擊界面控制不同物體的移動以及不同的行為也是非常難的。
星海爭霸 2 的這些特質,恰恰是人工智能在創新之路上需要挑戰的——面對許多難以預測的突發情況,人工智能必須要既作出正確的對策,還要根據實際情況細微的調整對策。

(來源:DeepMind)
星海爭霸 2 作為"即時戰略"遊戲,其"即時"和"戰略"的特性無疑是鍛煉 AI 的最佳途徑之一。就拿"即時"來說,或許對於人類,星際 2 的那 300 多個基礎操作的"操作空間"(Action Space)並不龐大。但是對於機器,星際 2 的分級操作,外加"升科技"所帶來指令的變化,再加上地圖的體積,其操作空間是無窮大的。比如"農民建房子"這個簡單的行動就有 6 個不同的步驟:點擊滑動滑鼠選擇部門,B 選擇建造,S 選擇供給站,滑動滑鼠選擇位置,點擊建造。僅在一個 84x84 的螢幕上,機器的操作空間有大約 1 億個可能的操作。
AlphaGo Zero 創造者:"這個比圍棋難多了"
在 DeepMind 與暴雪長期以來的合作中,有幾個重要節點:
2017 月 8 月,星海爭霸 2 開發團隊發布人工智能研究環境 SC2LE(StarCraft II Learning Environment),它包括一個能讓研究人員和開發人員與遊戲掛鉤的機器學習 API,開放了 65000 場比賽的數據緩存,以及 50 萬次匿名遊戲回放和其他研究成果。其中一些數據對於訓練和輔助序列預測和長期記憶研究非常有用,當時團隊也希望通過這些工具,幫助研究人員加快星海爭霸 2 AI 的開發速度。

圖丨 Julian Schrittwieser(來源:麻省理工科技評論)
SC2LE 發布不久以後,AlphaGo Zero 創造者之一、《麻省理工科技評論》TR 35 獲得者 Julian Schrittwieser 在在一場網絡互動中表示:星海爭霸 2 的 AI 尚處早期,研發難度比圍棋人工智能更大,在 AlphaGo Zero 誕生之後,團隊希望能以此為契機,在 AI 研究上再次實現突破。
團隊與星海爭霸 2 相關的第一篇公開論文,則出現在 2018 年 6 月。當時,DeepMind 在 arXIv 發布其最新研究成果:用關係性深度強化學習在星際 2 六個模擬小遊戲(移動、采礦、建造等)中達到了當前最優水準,其中四個超過人族天梯大師組玩家。
之後,直到 2018 年 11 月,在暴雪的一場展會上,我們才再次得知這個項目的進展——DeepMind 團隊曾展示了能夠執行基本的集中策略以及防禦策略的人工智能進展:在掌握遊戲的基本規則後,它就會開始表現出有趣的行為,比如立即衝向對手攻擊,研究團隊還公布其 AI 在對抗"瘋狂"電腦時也有 50% 的勝率。
對比 3 個月後的今天,從 DeepMind AI 在比賽中的表現,不得不說其進步之快。
接下來另一場值得期待的"大戰",將發生在 2 月 15 日:在星海爭霸 2 AI 直播預告公布後,芬蘭電競戰隊 ENCE 也發布通告,稱 WCS 星海爭霸 2 全球總冠軍芬蘭選手 Serral 將在與星際 2 人工智能上演一場人機大戰。屆時 AI 與人類頂尖選手的對戰,或許還將會再次創造新的歷史事件。

圖 | ENCE通告(圖源:Twitter)
今年的"人機大戰"看什麽?打造通用性 AI 依然"道阻且長"
近幾年,除了 DeepMind 以外,已經有越來越多的人工智能公司或者研究機構投身到開發遊戲類AI的浪潮中,例如 OpenAI 和騰訊的 AI lab 等等。
歸根結底,這些團隊對遊戲AI的熱情,恐怕都源於打造通用型人工智能的這一終極目標:遊戲AI的研發將會進一步拓寬人類對於AI能力的認知,這樣的研究最終將探索的問題 AI 能否能夠通過遊戲規則進行自主學習,達到更高層次的智能乃至通用型人工智能。例如,在遊戲AI的設計中,增強學習算法的改進將至關重要。增強學習是一種能夠提高 AI 能力的核心算法,它讓 AI 能夠解決具有不確定性動態的決策問題(比如遊戲 AI,智能投資,自動駕駛,個性化醫療),這些問題往往也更加複雜。
而 DeepMind 團隊的成果已經為此帶來了一絲曙光——AlphaGo Zero在短時間內精通圍棋、象棋、國際象棋三種棋類遊戲,已有棋類通用AI雛形。棋類遊戲之後,最值得期待的進展,就是各家開發的AI在即時戰略類 RTS 遊戲或多人在線競技類 MOBA 遊戲上的表現了。此前,騰訊 AI Lab 負責人之一姚星就介紹過,在遊戲AI的研究上,騰訊 AI Lab 已從圍棋 AI “絕藝”等單個 AI 的完全資訊博弈類遊戲,轉移到規則不明確、任務多樣化、情況複雜的遊戲類型,如星海爭霸和 Dota2 等複雜的即時戰略類 RTS 遊戲或多人在線競技類 MOBA 遊戲。

圖丨OpenAI 宣布他們所打造的一個 AI 機器人已經在電子競技遊戲 Dota 2 中擊敗了一個名為 Dendi 的人類職業玩家(來源:OpenAI)
在剛剛過去的2018年,OpenAI 開發出的 AI OpenAI Five 就是針對 Dota2 開發的AI,但是它與人類 PK 的過程可謂充滿戲劇性。2018 年 8 月初,OpenAI Five 戰勝一支人類玩家高水準業餘隊伍(天梯 4000 分左右),然而,到了 8 月底 OpenAI Five 被兩支專業隊伍打敗, AI 提前結束了其在本屆 DOTA 2 國際頂尖賽事 TI 8 的旅程。回顧那次失敗的過程,其實OpenAI 的系統仍然無法全面理解 DOTA 複雜的遊戲系統和規則。
現在,DeepMind 的星海爭霸2 AI 已經以其超強實力打響遊戲 AI 2019 年第一戰,接下來還有哪些遊戲AI將橫空出世呢?各大遊戲AI又將如何邁向通用人工智能,讓我們拭目以待。