幾十年來,遊戲是一直被用作測試和評估AI(人工智能系統)性能的重要方法。隨著能力的不斷提高,研究者們開始尋求越來越複雜的遊戲,這些遊戲擁有可以用來解決科學和現實問題所需的多種智能要素。《星海爭霸》則被公認是最具挑戰性的即時戰略遊戲(RTS)之一,也是有史以來遊戲時長最長的電子競技之一,已成為AI研究的"重大挑戰"。

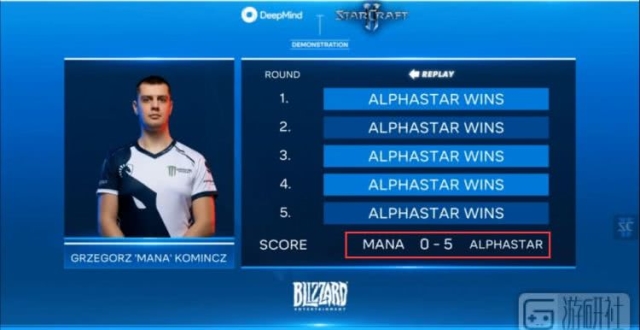
台灣時間1月25日凌晨2點,AI選手AlphaStar完成了他們的《星海爭霸2》首秀,需要特別注意的是,這次參加挑戰的AI並非一位,而是三位,他們被統稱為AlphaStar。

DeepMind團隊在這次挑戰中研究出了多款AlphaStar,這些AlphaStar最先通過研究上百萬份《星海爭霸2》玩家天梯錄像進行自我學習,然後再進入一種類似於"AlphaStar聯賽"的互相訓練賽模式進行學習,這種左右互搏之術讓AlphaStar成長創造出自己的三種不同"自我"型號,分別是:"普通型"、"極致操作不敗型"、"擬人型"。

經過一個星期的學習之後,AlphaStar已經能夠擊敗研究所內最會打星際的研究員(大約天梯5000分實力)。

與人類高手同台競技
起初,最先與AlphaStar對戰的是來自Liquid戰隊的TLO,這位曾經的天才少年現在已經遠不如前,水準退步的很厲害,目前他在神族歐服天梯也就是5500分左右的水準(TLO主玩蟲族,水準尚可),在研究人員看來,作為AlphaStar的出山第一戰,這個水準用來給AlphaStar露露臉是再適合不過了。

事實證明AlphaStar遠超所有人的預期,或者換句話說,TLO打的太菜,也遠超所有人的預期,TLO的神族用辣眼睛來形容真是再貼切不過了——第一局,AlphaStar還沒有發力,TLO就倒下了,而這時候的AlphaStar在"會玩"遊戲的玩家們眼中,卻可以說是漏洞百出,絲毫沒有什麽遊戲理解。

7分鐘的對局讓我們第一次正面了解了AlphaStar,但是他許多奇怪的操作讓人無法理解:一個有上萬場錄像學習經驗的AI,居然學不會職業玩家的建築學,不會堵口這種戰術也就算了,居然自己修水晶阻擋農民采集氣體,更令人不可思議的是AlphaStar在單礦運營農民達到上限的時候竟然持續生產農民,這一系列不符合常規理解的操作讓人直呼看不懂!

然而細心的觀眾可能已經發現了,AlphaStar在單礦有21超負荷農民運營的時候,他的實際每分鐘收入是超過TLO的——可能這就是AI並不會墨守成規的一點,他通過自己的學習和對遊戲的理解,對暴雪訂製的遊戲運營規則發出了自己的質疑。在AlphaStar看來,並非16農民采集就是單礦的上限。
經歷了第一盤潰敗的TLO很明顯已經亂了陣腳,後續4場比賽也是一敗塗地,然而值得我們關注的是,此時的AlphaStar確實還不夠強大。首先,AlphaStar的操作經常出現問題,控制部門一多,甚至會出現用自爆球炸自己的鏡頭,其次是他對遊戲理解產生了一定的問題,隱身偵查部門OB他竟然一生產就是5個,並且沒有分散使用,這種小細節上暴露的問題顯得十分可笑。

AlphaStar進攻中失誤,誤傷自己部門,瞬間損失近20人口部隊

5OB集體巡航讓玩家懷疑人生
AlphaStar用一陣亂拳打死老司機的操作抬走了TLO,這下可把DeepMind團隊樂的笑出了聲,趕忙邀請了正經八百的神族現役一線職業選手MANA前來對陣。

同為Liquid的職業選手,MANA就要強勢的多了。儘管隊友已經敗給了AlphaStar,但是他有足夠的信心去擊敗這個AI,畢竟世界前十的神族選手對戰一個隻學習了兩周的AI,就單看第一輪的結果來說,應該是沒有任何問題的,這種實力至上的對話,上屆WCS亞軍完全不虛。

然而,比賽並沒有按照預想的發展,起碼沒有按照MANA預想的那麽來——AlphaStar再次閉關修行一周後,已經脫胎換骨,依然堅持自己的25農民單礦超負荷運載,一波2BG+野2BG走路續兵直接換家MANA,僅僅5分鐘就兵不血刃拿下首勝。

第二盤的時候AlphaStar拿出了自己之前從未展現的鳳凰+追獵組合,鳳凰的操控精準飄逸,每一步走位都遊離在MANA的攻擊距離邊緣,精準的控血讓AlphaStar佔盡了便宜,兩三波交換下來,AlphaStar部隊保存完好,MANA卻被左右包夾和各種秀操作到死。

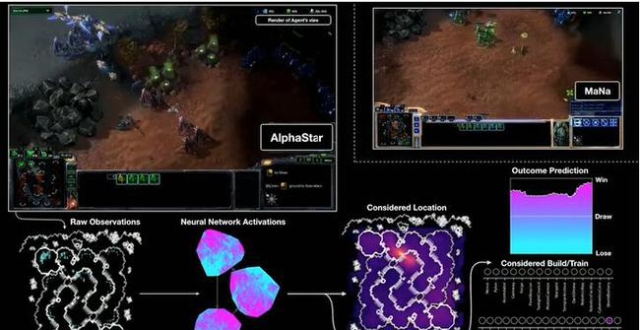
通過這張GIF我們清晰的可以看到,在與MANA比賽期間,AlphaStar的各種操作其實都是由神經網絡的原始觀察輸入系統(左下),然後神經網絡內部開始激活分析處理數據(中下),隨後AI得出自己的判斷,開始進行操作,生產部門、控制部門,與此同時AlphaStar還在同步的計算自己的勝率。而在AlphaStar眼中,在這波交戰過後,MANA幾乎再無任何翻盤的機會。

簡單來說,第三盤全面爆發的MANA拿出了自己的真本事,然而也只是前期稍佔優勢,後期AlphaStar甚至使用了主動示弱,誘敵深入的方式將MANA主力三面圍殲在外,擁有瞬時間上千有效APM,無敵操作的AlphaStar摧枯拉朽,一擊就徹底擊垮了MANA。

AlphaStar自信勝率拉滿
第五局則更加飄逸,AlphaStar甚至主動去封了MANA的氣礦,出其不意的打出了野不朽的戰術爆錘MANA,打的世界亞軍苦笑連連,畢竟他知道自己會輸是因為被機器硬吃了操作,這並不丟人。
最後,作為今日直播的壓軸戲,MANA現場又和AlphaStar來了一次對決,這次的AlphaStar全新版本實力更加強大,初期甚至學會了騷擾經濟,他選擇了出先知來破壞對方農民采集資源,自己依然多BG正面暴兵,運營上面更是誇張的開到了三礦。
就當觀眾們以為這種"無解肥"的AlphaStar要一波流取勝時,MANA神奇的用一個棱鏡帶倆不朽空投騷擾AlphaStar主基地,AlphaStar竟然撤回了原本出征的大部隊,全員回防,MANA一看對手全部回家,立馬撤退,打起了遊擊,兩三個回合下來,竟然把AlphaStar困在基地內無法出門。(很明顯MANA發現了這個問題,AlphaStar竟然不懂得分兵!)

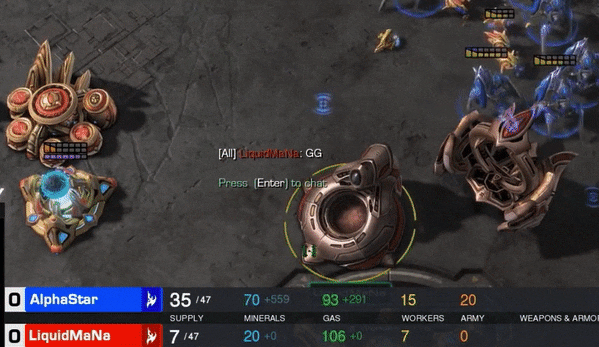
這一幕神似日常單機遊戲中卡了BOSS的BUG,邪惡的勇士一刀一刀凌遲了中了BUG無法還手的BOSS。然後MANA喘過氣來反手就是一個巴掌,順勢拿下了只會出追獵和先知的AlphaStar,取得了《星海爭霸2》上人類對戰AI的首勝。


在DeepMind給出的資料我們可以清晰的看到AlphaStar的學習成長曲線,在"AlphaStar聯賽"中開始他們只有2500分左右的水準,然而一周時間的訓練,他們就飆升至5500分左右可以和TLO相抗衡。又用了一周時間,對陣MANA這種7000分的頂級神族也不在話下。

AlphaStar聯賽——在無數個AlphaStar AI內部進行的對抗系統,在整個項目當中也功不可沒。而頗為有趣的一點是,此次出戰的三個AlphaStar,是從無數個AI當中廝殺出來的,表現最為優異的幾個,而剩下的那些則遭到無情淘汰,這種養蠱模式也頗有些"大逃殺"的味道。
AI們最初通過研究人類玩家的錄像進行訓練,然後和聯賽中的其他AI進行訓練。在每次循環中,新的參賽者從原來的競爭者中分支出來,而原來的參賽者被凍結。同時可以調整確定每個可能已經適應的智能體的學習目標的匹配概率和超參數,從而在保持多樣性的同時增加難度。通過從參賽者的遊戲結果中加強學習來更新代理的參數。 最終的AI從聯賽的納什分布中抽樣選出。
然而你所不知道的是,最強款的AlphaStar一周練習量相當於人類200年的練習量,這一點酷似當初的圍棋AI——AlphaGO。DeepMind使用了一種"關係性深度強化學習"的方法。打個比方,遊戲中一個鳳凰是選擇抬哨兵還是追獵,這個選擇在AI的眼裡是個概率問題,而如何讓這個概率選擇趨於最優化,就需要AI大量的學習迭代。
要知道在圍棋的世界裡,僅有19X19棋盤,也就是361個落點需要計算,而星際2中,需要計算的量是10^26,這一天文數字的變量讓AI舉步維艱,但是一旦破局成功,AI的成長也是驚人。
DeepMind研發的AlphaStar超出了所有人的想象,得益於他們技術和資本的優勢,他們擁有超群的TPU算力,舉個例子,普通AI團隊能夠讓他們的AI每天練習學習數十局,而DeepMind可以讓他們的AI每天練習學習一百萬局。
為什麽在對戰MANA的前5盤都能乾淨利落的拿下比賽,其實AlphaStar也是耍了自己的"小聰明",在十二月版本的AlphaStar,他們采取的觀察手段是通過小地圖去以"天眼"的姿態俯瞰全局,也就是任何風吹草動,只要是發生在小地圖裡會顯示的資訊,都難逃AlphaStar的"天眼"(也即是不用切屏也能獲得切屏才能獲得的資訊)。

這種"不公平"的手段產生了巨大的優勢,畢竟人類玩家很難做到一邊打遊戲一邊全神貫注的盯著小地圖不放過任何一個細節,因此新版本的AlphaStar修改了鏡頭的算法,他現在也和人類一樣,只能通過螢幕的切換觀察戰場上的瞬息萬變,而直播中最後的表演賽,上場的就是使用人類視角的新版AlphaStar。

新的AlphaStar隻用了短短7天就追趕接近了原先"天眼"系統,甚至在一次"AlphaStar訓練賽"中擊敗了"天眼AlphaStar"。

各個選手APM分布,以及AlphaStar在觀察和行動之間的延遲分布
然而勝利也並非完全依賴操作,AlphaStar的操作被精準的限制在了450APM,EPM則是180,這一數據遠低於頂級選手的爆發操作,而且AlphaStar的反應速度也被限制在了300MS,其實這已經比人慢很多了。但是,這看似正常的數據背後,是一個沒有疲勞,0廢操作,每一下都下達有效指令的AI,效率轉化十分驚人。
在DeepMind的結論下,AlphaStar對戰MANA和TLO的成功都是基於卓越的巨集觀和微觀的戰略決策,而不是取決於腳本版的操作,或者閃電般的反應速度。然而吃瓜群眾也不用擔心太多,人類之所以為人類,就是能從不同的結果中學習,DeepMind就是希望能夠找出一個能和人類一樣自我學習的算法,這個長期的計劃對於人類的未來意義重大。

主要參考來源:
DeepMind官網
論文《Relational Deep Reinforcement Learning》(關係性深度強化學習)
同時感謝國內AI領域專家"飛羽"博士對本文的大力支持!
本文僅代表訂閱平台作者觀點,與本站立場無關。遊民星空僅提供發布平台。未經允許嚴禁轉載。