基於深度學習的現代電腦視覺模型,其性能主要取決於的大量已標注的可用訓練數據集,例如 Open Images 數據集。然而,如何獲得高品質的訓練數據,成為電腦視覺發展的主要瓶頸。如在無人駕駛、機器人和影像搜索之類的應用中,使用的一些像素級目標預測任務,比如語義分割任務,格外的需要更大更好的數據集。事實上,傳統的手工標注工具需要標注人仔細點擊影像中每個對象的邊界,用來劃分影像中的目標,這項工作非常乏味:COCO+Stuff 數據集得標注單個影像就需要大概 19 分鐘,而標記整個數據集甚至需要 53000 個小時!
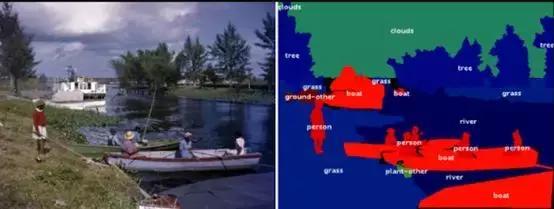
左圖| COCO 數據集中的一張圖片; 右圖|左圖的像素級語義分割結果。(來源:Image credit)
谷歌的研究人員設計了一種機器學習驅動的工具,將在 2018 年 ACM 多媒體會議的“ Brave New Ideas ”環節展示,可以用於標注影像數據中每個目標的輪廓和背景,將其應用在標注分類數據上,可以讓標記數據集的生成速度提高至傳統方法的 3 倍。
該方法被谷歌稱之為流體標注(Fluid Annotation),從強語義分割模型的輸出開始,人工標注者可以使用用戶界面,通過機器輔助方法進行編輯修改。谷歌開發設計的界面允許標注者選擇要改正的內容和順序,讓他們能集中精力去處理機器尚未理解和標注的影像。

圖 | 對 COCO 數據集中的影像使用流體標注的可視化界面。(來源:gamene)
為更準確的對影像進行標注,谷歌首先通過預訓練的語義分割模型(Mask-RCNN)來處理影像。這一過程會生成約 1000 個影像分割區域及其標簽和置信度。置信度最高的分割區域用來初始化標簽,呈現給標注者。
然後標注者可以:
(1)從機器生成的候選分類標簽中為當前區域選擇標簽。(2)對機器未覆蓋到的目標添加分割區域。機器會識別出最可能的預生成區域,標注者從中選擇分割效果最好的一個。(3)刪除現有分割區域。(4)改變重疊區域的深度順序。
Demo 鏈接:
https://fluidann.appspot.com(PC 平台可用)

圖 |使用傳統人工標注工具(中列)和流體標注工具(右列)在 COCO 數據集的三張影像上比較標注結果。雖然使用人工標注工具時,目標的邊界一般更準確,但同一對象的標注有時會存在差異,其主要是因為人類標注者通常對某一確定目標的類別有不同意見。圖片來源:sneaka(上),Dan Hurt(中),Melodie Mesiano(下)。
在讓影像標注變得更快、更容易這個問題上,流體標注工具的出現只是第一步。未來團隊的目標是改進對目標邊界的標注,進一步利用人工智能提升界面運行速度,最終可以處理以前無法識別的類別,讓數據收集變得越來越高效和快捷。








