機器之心原創
作者:思源、劉曉坤
2018 年即將結束,要問今年深度學習領域有什麽要關注的進展,恐怕首先想到的就是 Deepmind 的 BigGAN 和 Google 的 BERT。這兩項進展有一些共同點:除了弱監督或無監督,那就是大,數據大,模型大,計算大,算法改動沒那麽大,主要靠計算。
但是除了它們,今年還是有很多非常美的想法,例如強行解積分的強大流模型 Glow、基於圖結構的廣義神經網絡,以及擁有連續層級的神經常微分方程。它們為深度學習開拓了新方向,也為未來提供了更多選擇。
在這篇文章中,機器之心從想法到實踐介紹了 2018 年令人矚目的研究工作,它們共同構建了機器學習的當下。我們主要按領域從模型到開源工具展開,其中算法或模型的選擇標準主要是效果和潛力,而開源工具的選擇主要憑借 GitHub 的收藏量與效果。本文的目錄如下所示:
自然語言處理
預訓練語言模型
機器翻譯
谷歌 Duplex
生成模型
大大的 GAN
流模型
神經網絡新玩法
圖神經網絡
神經常微分方程
電腦視覺
視覺遷移學習
強化學習與遊戲
徳撲
星海爭霸
Dota
量子計算
絕對界限
相對界限
開源工具
強化學習框架 Dopamine
圖網絡庫(Graph Nets library)
圖神經網絡框架 DGL
Auto Keras
TransmogrifAI
目標檢測框架 Detectron
NLP 建模框架 PyText
BERT 開源實現
大規模稀疏框架 XDL
面向前端的 TensorFlow.js
自然語言處理
在即將過去的 2018 年中,自然語言處理有很多令人激動的想法與工具。從概念觀點到實戰訓練,它們為 NLP 注入了新鮮的活力。其中最突出的就是機器翻譯與預訓練語言模型,其中機器翻譯已經由去年的 Seq2Seq 到今年大量使用 Transformer,而預訓練語言模型更是從 ELMo 到
BERT
有了長足發展。
預訓練語言模型
大概在前幾年,很多人認為預訓練的意義不是特別大,都感覺直接在特定任務上做訓練可能效果會更好。但是隨著電腦視覺領域中預訓練模型的廣泛使用,很多 NLP 的研究者也在思考是不是能有一種方法,它可以將通用的語言知識遷移到不同的 NLP 任務中。
很快大家就選定了語言模型,首先它是一種無監督方式,所以訓練樣本很容易獲取。其次語言模型能預測一個詞序列是人類話語的概率,因此某種意義上它包含了通用的語言知識。因此在 2018 年中,使用預訓練語言模型可能是 NLP 領域最顯著的趨勢,它可以利用從無監督文本中學習到的「語言知識」,並遷移到各種 NLP 任務中。
這些預訓練模型有很多,包括 ELMo、ULMFiT、OpenAI Transformer 和 BERT,其中又以 BERT 最具代表性,它在 11 項 NLP 任務中都獲得當時最佳的性能。不過目前有 9 項任務都被微軟的新模型超過。
ULMFiT
ULMFiT 由 Sebastian Ruder 和 fast.ai 的 Jeremy Howard 設計,是首個將遷移學習應用於 NLP 的框架。ULMFiT 表示 Universal Language Model Fine-Tuning(通用語言模型微調)。ULMFiT 真的實現了「通用」,該框架可用於幾乎所有 NLP 任務。
論文:Universal Language Model Fine-tuning for Text Classification
論文地址:https://arxiv.org/pdf/1801.06146.pdf
ULMFiT 最好的地方在於我們不用再從頭訓練模型了。研究者把最難的部分做好了,直接將他們做好的模型用到自己的項目中即可。ULMFiT 在六個文本分類任務上優於之前最優的方法。
ULMFiT 主要可以分為三個階段:
在通用領域實現語言模型的預訓練
在目標任務實現語言模型的微調
在目標任務的分類器微調

如上所示,ULMFiT 主要由三階段組成。(a)中的預訓練語言模型能捕獲自然語言的一般特徵,而(b)中的語言模型會使用判別性的微調(Discr)和斜三角式的學習率來進行調整,它將在目標任務上學習到特定的特徵。最後(c)表示分類器在目標任務上的微調,其中灰色表示不固定權重的階段,而黑色表示固定權重的階段,這樣能保留低級表示而適應地調整高級表示。
感興趣的讀者可參考以下內容:
https://github.com/prateekjoshi565/ULMFiT_Text_Classification
http://nlp.fast.ai/category/classification.html
ELMo
ELMo 是 Embeddings from Language Models 的縮寫。ELMo 一經發布即引起了機器學習社區的關注,它使用語言模型來獲取每個單詞的詞嵌入,同時考慮單詞在句子或段落中的語境。這種添加了語境資訊的詞表征可以表示複雜的語言知識,因此也就可以編碼整個句子的資訊。
論文:Deep contextualized word representations
論文鏈接:https://arxiv.org/pdf/1802.05365.pdf
具體而言,研究者使用從雙向 LSTM 中得到的向量,該 LSTM 是使用正向和反向兩個語言模型(LM)在大型文本語料庫上訓練得到的。用這種方式組合內部狀態可以帶來豐富的詞表征。研究者使用內在評價進行評估,結果顯示更高級別的 LSTM 狀態捕捉詞義的語境依賴方面(如它們不經修改就可以執行監督式詞義消歧任務,且表現良好),而較低級別的狀態建模句法結構(如它們可用於詞性標注任務)。同時揭示所有這些信號是非常有益的,可以幫助學得的模型選擇對每個任務最有幫助的半監督信號。
與 ULMFiT 類似,ELMo 極大提升了在大量 NLP 任務上的性能,如情感分析和問答任務。如下展示了 ELMo 在不同 NLP 任務中的效果,將 ELMo 加入到已有的自然語言系統將顯著提升模型效果。

更多資訊及預訓練 ELMo 模型可查看:https://allennlp.org/elmo
BERT
BERT 是一種新型語言表征模型——來自 Transformer 的雙向編碼器表征。與最近的語言表征模型不同,BERT 旨在基於所有層的左、右語境來預訓練深度雙向表征。BERT 是首個在大批句子層面和 token 層面任務中取得當前最優性能的基於微調的表征模型,其性能超越許多使用任務特定架構的系統,刷新了 11 項 NLP 任務的當前最優性能記錄。
機器之心曾解讀過 BERT 的的核心過程,它會先從數據集抽取兩個句子,其中第二句是第一句的下一句的概率是 50%,這樣就能學習句子之間的關係。其次隨機去除兩個句子中的一些詞,並要求模型預測這些詞是什麽,這樣就能學習句子內部的關係。最後再將經過處理的句子傳入大型 Transformer 模型,並通過兩個損失函數同時學習上面兩個目標就能完成訓練。

如上所示為不同預訓練模型的架構,BERT 可以視為結合了 OpenAI GPT 和 ELMo 優勢的新模型。其中 ELMo 使用兩條獨立訓練的 LSTM 獲取雙向資訊,而 OpenAI GPT 使用新型的 Transformer 和經典語言模型只能獲取單向資訊。BERT 的主要目標是在 OpenAI GPT 的基礎上對預訓練任務做一些改進,以同時利用 Transformer 深度模型與雙向資訊的優勢。
這種「雙向」的來源在於 BERT 與傳統語言模型不同,它不是在給定所有前面詞的條件下預測最可能的當前詞,而是隨機遮掩一些詞,並利用所有沒被遮掩的詞進行預測。
此外,BERT 的開源項目非常有誠意,谷歌研究團隊開放了好幾種預訓練模型,它們從英語到漢語支持多種不同的語言。很多開發者在這些 BERT 預訓練語言模型上做二次開發,並在不同的任務上獲得很多提升,BERT 開源項目將放在文章後面,並與其它開源庫一起介紹。
機器翻譯
在 2018 年裡,神經機器翻譯似乎有了很大的改變,以前用 RNN 加上注意力機制打造的 Seq2Seq 模型好像都替換為了 Tramsformer。大家都在使用更大型的 Transformer、更高效的 Transformer 組件。例如阿里根據最近的一些新研究對標準 Transformer 模型進行一些修正。這些修正首先體現在將 Transformer 中的 Multi-Head Attention 替換為多個自注意力分支,其次他們採用了一種編碼相對位置的表征以擴展自注意力機制,並令模型能更好地理解序列元素間的相對距離。
有道翻譯也採用了 Transformer,他們同樣會采取一些修正,包括對單語數據的利用、模型結構的調整、訓練方法的改進等。例如在單語數據的利用上,他們嘗試了回譯和對偶學習等策略,在模型結構上採用了相對位置表征等。所以總的而言,儘管 Transformer 在解碼速度和位置編碼等方面有一些缺點,但它仍然是當前效果最好的神經機器翻譯基本架構。
Sebastian Ruder 非常關注無監督機器翻譯模型,如果無監督機器翻譯模型是能行得通的,那麽這個想法本身就很驚人,儘管無監督翻譯的效果很可能遠比有監督差。在 EMNLP 2018 中,有一篇論文在無監督翻譯上更進一步提出了很多改進,並獲得極大的提升。Ruder 筆記中提到了以下這篇論文:
論文:Phrase-Based & Neural Unsupervised Machine Translation
論文鏈接:https://arxiv.org/abs/1804.07755
這篇論文很好地提煉出了無監督 MT 的三個關鍵點:優良的參數初始化、語言建模和通過回譯建模反向任務。這三種方法在其它無監督場景中也有使用,例如建模反向任務會迫使模型達到循環一致性,這種一致性已經應用到了很多任務,讀者最熟悉的可能是 CycleGAN。該論文還對兩種語料較少的語言做了大量的實驗與評估,即英語-烏爾都語和英語-羅馬尼亞語。

無監督 MT 的三個主要原則:A)兩種單語數據集、B)參數初始化、C)語言建模、D)回譯。
這篇論文獲得了 EMNLP 2018 的最佳長論文獎,它在遵循上面三個主要原則的情況下簡化了結構和損失函數,得到的模型優於以前的方法,並且更易於訓練和調整。
谷歌 Duplex
2018 谷歌 I/O 開發者大會正式介紹了一種進行自然語言對話的新技術 Google Duplex。這種技術旨在完成預約等特定任務,並使系統盡可能自然流暢地實現對話,使用戶能像與人對話那樣便捷。Duplex 基於循環神經網絡和 TensorFlow Extended(TFX)在匿名電話會話數據集上進行訓練。這種循環網絡使用谷歌自動語音識別(ASR)技術的輸出作為輸入,包括語音的特徵、會話歷史和其它會話參數。谷歌會為每一個任務獨立地訓練一個理解模型,但所有任務都能利用共享的語料庫。此外,谷歌還會使用 TFX 中的超參數優化方法優化模型的性能。
如下所示,輸入語音將輸入到 ASR 系統並獲得輸出,在結合 ASR 的輸出與語境資訊後可作為循環神經網絡的輸入。這一深度 RNN 最終將基於輸入資訊輸出對應的響應文本,最後響應文本可傳入文本轉語音(TTS)系統完成對話。RNN 的輸出與 TTS 系統對於生成流暢自然的語音非常重要,這也是 Duplex 系統關注的核心問題。

在 Duplex 系統的語音生成部分,谷歌結合了拚接式的 TTS 系統和合成式的 TTS 系統來控制語音語調,即結合了 Tacotron 和 WaveNet。
生成模型
生成對抗網絡在 2018 年仍然是研究的重點,我們不僅看到可以生成高分辨率(1024×1024)影像的模型,還可以看到那些以假亂真的生成影像。此外,我們還很興奮能看到一些新的生成模型,它們沒有採用對抗式的訓練方式,其主要代表就是流模型 Glow。
大大的 GAN
今年 9 月份,DeepMind 團隊創造出「史上最強 GAN」,該研究被接收為 ICLR 2019 的 oral 論文。很多學者驚呼:不敢相信這樣高品質的影像竟是 AI 生成出來的。
論文:LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
論文地址:https://arxiv.org/pdf/1809.11096.pdf

BigGAN 生成影像的目標和背景都高度逼真、邊界自然,並且影像插值每一幀都相當真實,簡直能稱得上「創造物種的 GAN」。當在 128x128 分辨率的 ImageNet 上訓練時,BigGAN 可以達到 166.3 的 Inception 分數(IS),而之前的最佳 IS 僅為 52.52。
研究者還成功地在 256x256 分辨率和 512x512 分辨率的 ImageNet 上訓練了 BigGAN,並得到非常逼真的影像。但這麽好的效果,是靠巨大的計算力來推動。在原論文中,DeepMind 表示 BigGAN 會在谷歌 TPU v3 pod 上訓練,且根據任務使用不同的核心數,128x128 的影像使用 128 個核心數(64 塊芯片),512x512 的影像使用 512 個核心數(256 塊芯片)。
此外,今年 12 月,NVIDIA提出了另一種高精度 GAN。這款新型 GAN 生成器架構借鑒了風格遷移研究,可對高級屬性(如姿勢、身份)進行自動學習和無監督分割,且生成影像還具備隨機變化(如雀斑、頭髮)。
論文:A Style-Based Generator Architecture for Generative Adversarial Networks
論文鏈接:https://arxiv.org/pdf/1812.04948.pdf
NVIDIA提出的這種基於風格的生成器能構建非常高分辨率的人臉影像,即 1024×1024 分辨率的影像,詳情可查看以下影片:

流模型
目前,生成對抗網絡 GAN 被認為是在影像生成等任務上最為有效的方法,越來越多的學者正朝著這一方向努力:在電腦視覺頂會 CVPR 2018 上甚至有 8% 的論文標題中包含 GAN。今年來自 OpenAI 的研究科學家 Diederik Kingma 與 Prafulla Dhariwal 卻另辟蹊徑,他們提出了基於流的生成模型 Glow。據介紹,該模型不同於 GAN 與 VAE,在生成影像任務上也達到了令人驚豔的效果。
該研究一經發表,立刻引起了機器學習社區的注意,很多研究者表示:終於,我們有了 GAN 以外的優秀生成模型!
論文:Glow: Generative Flow with Invertible 1×1 Convolutions
論文地址:https://d4mucfpksywv.cloudfront.net/research-covers/glow/paper/glow.pdf
OpenAI 創造的 Glow 是一種使用可逆 1×1 卷積的可逆生成模型,它可以生成逼真的高分辨率影像,支持高效率采樣,並能發現用於操作數據屬性的特徵。目前,OpenAI 已經發布了該模型的代碼,並開放了在線可視化工具,供人們試用。

詳細的內容可參考機器之心的介紹性文章與蘇劍林發布在 PaperWeekly 的解讀:
神經網絡新玩法
今年有很多研究從理論分析方面或結合其它領域來擴展深度學習,其中最突出的就是 DeepMind 和谷歌大腦等研究機構提出的圖網絡(Graph Network),以及多倫多大學陳天琦等研究者提出的神經常微分方程。
前者提出的圖網絡是一種新的 AI 模塊,即基於圖結構的廣義神經網絡,圖網絡推廣了以前各種對圖進行操作的神經網絡方法。借助微分方程,後者提出的 ODEnet 將神經網絡離散的層級連續化了,因此反向傳播也不再需要一點一點傳、一層一層更新參數。
圖網絡
圖+深度學習一直都有很多研究工作,但今年最引人矚目的是圖網絡(Graph Network),它由 DeepMind、谷歌大腦、MIT 和愛丁堡大學等公司和機構的 27 位科學家共同提出。
論文:Relational inductive biases, deep learning, and graph networks
論文地址:https://arxiv.org/pdf/1806.01261.pdf
該論文提出的圖網絡(GN)框架定義了一類對圖結構表征進行關係推理的函數。該 GN 框架泛化並擴展了多種圖神經網絡、MPNN 和 NLNN 方法,並支持從簡單的構建模塊建立複雜的架構。注意,這裡避免了在「圖網絡」中使用「神經」術語,以反映它可以用函數而不是神經網絡來實現,雖然在這裡關注的是神經網絡實現。
目前圖網絡在監督學習、半監督學習和無監督學習等領域都有探索,因為它不僅能利用圖來表示豐富的結構關係,同時還能利用神經網絡強大的擬合能力。
一般圖網絡將圖作為輸入,並返回一張圖以作為輸入。其中輸入的圖有 edge- (E )、node- (V ) 和 global-level (u) 屬性,輸入也有相同的結構,只不過會使用更新後的屬性。如下展示了輸入圖、對圖實現的計算及輸出圖,更詳細的內容請參考原論文。

神經常微分方程
在今年 NeruIPS 2018 中,來自多倫多大學的陳天琦等研究者成為最佳論文的獲得者。他們提出了一種名為神經常微分方程的模型,這是一種新型深度神經網絡。神經常微分方程不拘於對已有架構的修修補補,它完全從另外一個角度考慮如何以連續的方式借助神經網絡對數據建模。
神經常微分方程走了另一條路線,它使用神經網絡參數化隱藏狀態的導數,而不是如往常那樣直接參數化隱藏狀態。這裡參數化隱藏狀態的導數就類似構建了連續性的層級與參數,而不再是離散的層級。因此參數也是一個連續的空間,我們不需要再分層傳播梯度與更新參數。
具體而言若我們在層級間加入更多的層,且最終趨向於添加了無窮層時,神經網絡就連續化了。我們可以將這種連續變換形式化地表示為一個常微分方程:

如果從導數定義的角度來看,當 t 的變化趨向於無窮小時,隱藏狀態的變化 dh(t) 可以通過神經網絡建模。當 t 從初始一點點變化到終止,那麽 h(t) 的改變最終就代表著前向傳播結果。這樣利用神經網絡參數化隱藏層的導數,就確確實實連續化了神經網絡層級。
現在若能得出該常微分方程的數值解,那麽就相當於完成了前向傳播。也就是說若 h(0)=X 為輸入影像,那麽終止時刻的隱藏層輸出 h(T) 就為推斷結果。這是一個常微分方程的初值問題,可以直接通過黑箱的常微分方程求解器(ODE Solver)解出來。而這樣的求解器又能控制數值誤差,因此我們總能在計算力和模型準確度之間做權衡。
如下所示,殘差網絡只不過是用一個離散的殘差連接代替 ODE Solver。

電腦視覺
視覺遷移學習
人類的視覺具備多種多樣的能力,電腦視覺界基於此定義了許多不同的視覺任務。長遠來看,電腦視覺著眼於解決大多數甚至所有視覺任務,但現有方法大多嘗試將視覺任務逐一擊破。這種方法造成了兩個問題:數據量大和冗余計算。
如果能有效測量並利用視覺任務之間的關聯來避免重複學習,就可以用更少的數據學習一組任務。Taskonomy 是一項量化不同視覺任務之間關聯、並利用這些關聯來最優化學習策略的研究,相關論文獲得了 CVPR 2018 的最佳論文獎。
如果兩個視覺任務 A、B 具有關聯性,那麽在任務 A 中習得的表征理應可為解決任務 B 提供有效的統計資訊。通過遷移學習,Taskonomy 計算了 26 個不同視覺任務之間的一階以及高階關聯。例如對於 10 個視覺問題,利用 Taskonomy 提供的學習策略最大可以減少 2/3 的訓練數據量。

由 Taskonomy 發現的一個示例任務結構。例如,從圖中可以發現通過將曲面法線估計器和遮擋邊緣檢測器學習到的特徵結合起來,用少量標注數據就能快速訓練用於重描影和點匹配的優質網絡。
抱歉我們今天想介紹的這篇論文,剛剛中了 CVPR 2018 最佳論文
強化學習與遊戲
博弈論存在兩種類型:完美資訊博弈和不完美資訊博弈。
不完美資訊博弈是指,博弈中的一個參與者不能知道其它參與者的所有行動資訊,比如德撲。如果將環境也考慮在內,參與者可能對環境的所知資訊也是不完美的,比如 MOBA(多人在線戰術競技遊戲,包括星海爭霸、Dota 等)。
圍棋、國際象棋都屬於完美資訊博弈,它們顯然不是今年的焦點。而德撲、星海爭霸和 Dota 都在今年取得了引人注目的成果。
德撲
2017 年 11 月,來自 CMU 博士生 Noam Brown 和教授 Tuomas Sandholm 的一篇論文確證獲得了 NeurIPS 2017 的最佳論文獎。
而在去年年初,在賓夕法尼亞州匹茲堡的 Rivers 賭場,CMU 開發的 Libratus 人工智能系統擊敗人類頂級職業玩家。此次比賽共持續 20 天,由 4 名人類職業玩家 Jason Les、Dong Kim、Daniel McAulay 和 Jimmy Chou 對戰人工智能程式 Libratus。在整個賽程中,他們總共對玩 12 萬手,爭奪 20 萬美元的獎金。最終的結果是「比賽過程中,人類選手整體上從未領先過。」
Sandholm 教授的獲獎論文,正是 Libratus 的技術解讀。他們針對德撲的不完美資訊博弈的特點,提出了一種無論在理論上還是在實踐上都超越了之前方法的子博弈求解技術。Libratus 也是第一個能在一對一無限注德州撲克單挑中打敗頂尖人類選手的 AI。

Libratus 在 2017 年 Brain vs. AI 大賽中的表現。
Libratus 並沒有使用深度學習方法,最主要的算法是 CFR,這是一種類似強化學習 self-play 的算法,但其還考慮了未被選擇的假設動作的收益。
由於序貫博弈在更深層階段計算成本高昂,Libratus 在前半場需要數百萬核心時間和數 TB 記憶體規模的資源。為此,他們在今年 5 月份又提出了一種在博弈的早期階段就對深度有限(depth-limited)的子博弈進行求解的新方法,實現了新的德撲 AI——Modicum,其只需要一台筆電電腦的算力就可以打敗業內頂尖的 Baby Tarta年n8(2016 電腦撲克冠軍)和 Slumbot(2018 年電腦撲克冠軍)。
關於 Libratus 和 AlphaGo 的對比,Noam Brown 曾經表示兩者解決的是不同的問題,不能直接對比:圍棋屬於完美資訊博弈,德撲屬於不完美資訊博弈。而在不完美資訊博弈領域中,Noam Brown 曾表示下一個突破很可能是在星海爭霸和 Dota(機智)。
星海爭霸
由於觀察空間和動作空間巨大、局部觀察(不完美資訊博弈)、多智能體同時遊戲、長期決策等因素,《星海爭霸 II》被認為是最難用 AI 攻克的遊戲。在這種設定下,研究人員還是不得不求助於深度學習和強化學習的結合。
今年,AI 界在《星海爭霸 II》可謂收獲頗豐。至少在特定設定下,我們已經攻克了全場遊戲。實現這一目標的包括騰訊 AI Lab、南京大學和伯克利。
今年 9 月,騰訊 AI Lab、羅切斯特大學和西北大學聯合提出了 TStarBots,在「深海暗礁地圖,蟲族 1 對 1」設定下在《星海爭霸 II》全場遊戲中打敗了難度為 1-10 級的內置 bot,其中 8、9、10 級的內置 bot 允許作弊行為。這是首個能夠在《星海爭霸 II》全場遊戲中擊敗內置 bot 的智能體。

TStarBot1 和 TStarBot2 智能體在不同難度等級下和內置 AI 比賽的勝率(100%)。
同樣在 9 月,南京大學也在《星海爭霸 II》上取得了突破。研究者讓智能體通過觀察人類專業選手遊戲錄像來學習巨集動作,然後通過強化學習訓練進一步的運營、戰鬥策略。他們還利用課程學習讓智能體在難度漸進的條件下逐步習得越來越複雜的性能。在 L-7 難度的神族對人族遊戲中,智能體取得了 93% 的勝率。這種架構也具有通用性更高的特點。
今年 11 月,伯克利在《星海爭霸 II》中提出了一種新型模塊化 AI 架構,該架構可以將決策任務分到多個獨立的模塊中。在蟲族對蟲族比賽中對抗 Harder(level 5)難度的暴雪 bot,該架構達到了 94%(有戰爭迷霧)的勝率。和 TStarBots 類似,他們也提出了分層、模塊化架構,並手工設計了巨集指令動作。伯克利的研究者解釋道,二者不同之處在於,他們的智能體是在模塊化架構下僅通過自我對抗及與幾個腳本智能體對抗來訓練的,直到評估階段才見到內建 bot。
三項研究各有千秋,對架構設計的考量圍繞著通用-專用權衡的主題,並且都抓住了巨集指令(巨集動作)定義的關鍵點,展示了分層強化學習的有效性。完全依靠深度學習和強化學習仍然不夠,結合人類定義的規則可以更有效地約束智能體的行為。至於可遷移性方面,或許南京大學提出的方法更具一般性。
Dota
2017 年 8 月,OpenAI 在 Dota2 TI 決賽現場以 1 對 1 solo 的方式擊敗了「Dota 2」世界頂級玩家。
今年,OpenAI 準備征服 5 v 5 團隊賽,可謂吊足了大眾的胃口。在正式征戰 TI 8 之前,OpenAI 陸續預演了好幾場熱身賽,並接連帶來驚喜。今年 6 月,OpenAI 宣布他們的 AI bot 在 5 v 5 團隊賽中擊敗業餘人類玩家,達到 4000 分水準。在 8 月初首次公開的基準測試賽中,OpenAI Five 以 2:1 的戰績擊敗了準職業玩家。
通過用機器學習取代硬編碼,並結合訓練環境隨機化擴大探索空間,得到魯棒的強化學習策略網絡,OpenAI 去年借此攻克了 Dota 中的一個小遊戲 Kiting,並成功遷移到了 1 v 1 模式中。而要進一步擴展到 5 v 5 團隊戰,最關鍵的一步就是擴大算力規模。OpenAI 最終使用了 128,000 CPU 核和 256 個 GPU 來支持算力,讓 AI 每天自我博弈成千上萬盤遊戲,每天累計遊戲時間達到 180 年。
人們原先認為,進行長時間和巨大探索空間的學習需要借助層級強化學習。然而,OpenAI 的結果表明,至少以足夠的規模和合理的探索方式運行的時候,一般的強化學習方法也能收獲奇效。
關於觀察空間,OpenAI 將 Dota2 世界表征為一個由 2 萬個數值組成的列表;關於動作空間,OpenAI 設定了一個包含 8 個枚舉值的列表,bot 根據這個列表的輸出采取行動。

OpenAI Five 的每一個 bot 都配置了一個 LSTM 來生成事件記憶,通過近端策略優化來進行自我對抗,並合理分配對手來避免策略模式匱乏。通過給未來獎勵設定合理的指數衰減,OpenAI Five 可以控制 bot 關注長期或者短期的獎勵。OpenAI Five 還設定了一個很巧妙的「團隊精神」參數,在訓練過程中逐漸從 0 增加到 1,可以讓 bot 從關注個人獎勵過渡到團隊獎勵,也就是從學習個人基本技能到學習團隊作戰策略。在某種程度上,這也可以說是一種隱含的層級強化學習。
OpenAI Five 從隨機參數開始,這些 bot 卻能從盲目遊走演變出 Dota 老司機非常熟悉的經典技能,令人驚歎。
在收獲讚譽的同時,對 OpenAI Five 的質疑也鋪天蓋地而來。
儘管是從隨機參數開始訓練,但 OpenAI Five 在嚴格意義上並不能說是「從零開始」訓練,並且其遊戲條件和人類玩家也有很大的不同。OpenAI Five 的 bot 的觀察輸入並不是遊戲界面的直接呈現,而是通過 API 讀取的結構化數據(也就是那 2 萬個數值組成的列表),各種距離度量都可以輕易完成,這和人類玩家的度量方式顯然大不相同,並具有精度和速度上的優勢。當然,目前的視覺強化學習仍然處於初步階段。而出現這些質疑也是合理的,畢竟攻克一個遊戲相對於遷移到現實世界而言,仍然只是個小問題。
關於英雄池的限制問題這裡就不討論了,感興趣的讀者可以參考機器之心的報導。
在 8 月末的 TI 8 正式比賽中,OpenAI Five 卻遭遇兩場連敗,尷尬收場。
至於下一步,OpenAI 是否會考慮《星海爭霸 II》AI 廣泛採用的層級強化學習呢?此外,以和玩家相同的遊戲界面作為觀察輸入進行視覺強化學習,這樣的結果是不是更能讓人信服呢?我們,再等等吧。
量子計算
量子計算在理論上超越了經典計算,卻給經典機器學習算法帶來了靈感。
絕對界限
電腦科學家 Ran Raz 和 Avishay Tal 證明只有量子電腦可以解決 forrelation 問題,而傳統電腦卻永遠無法解決。從計算複雜度的角度來講就是,他們找到了一個屬於 BQP、而不屬於 PH 的問題。其中,PH 涵蓋了任何可能的傳統電腦所能解決的問題,BQP 涵蓋了量子電腦可以解決的所有問題。
科學家早就證明 BQP 包含 P,但一直未能證明是否真包含 P。而 P∈NP∈PH,現在 Ran Raz 和 Avishay Tal 的結果也順帶證明了 BQP 真包含 P。

這個結果的意義還在於,即使將來人們證明 P=NP,傳統電腦和量子電腦之間仍然存在根本的區別。
相對界限
來自 UT Austin 的 Ewin Tang 提出了一種非常高效的「Quantum inspired」經典推薦系統算法,相比於之前的最快經典算法有指數級提高,並和量子推薦系統算法的速度相當。Tang 的結果讓人們看到了另一條路徑,即使傳統計算和量子計算存在絕對的界限,但對於具體的問題,還是可能找到類似計算複雜度的解法。畢竟這種界限的證明只是存在性的。在距離量子電腦實用還很遙遠的當下,或許「量子快速算法的經典化」是更值得探索的一個方向。就在近期,Tang 再次證明了低秩矩陣的量子矩陣求逆算法也存在有效的經典變體。

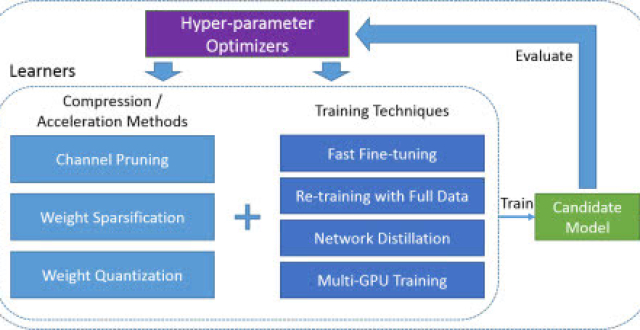
開源工具與庫
在過去的 2018 年中,不僅理論上有很多突破,實踐上也有非常多的開源工作。這些開源工作不僅包括已有項目的更新,同時還包括針對新想法的新項目。前者主要體現在 PyTorch 1.0、Julia 1.0 和 PaddlePaddle 1.0 等的發布,後者主要體現在 TensorFlow.js、Detectron、PyText 和 Auto Keras 等新項目的開源。
在這一部分中,我們主要關注今年發布的新項目,其它優秀項目的重大更新並不會包含在內。
強化學習框架 Dopamine
在過去幾年裡,強化學習研究取得了多方面的顯著進展。然而,大多數現有強化學習框架並不同時具備可讓研究者高效迭代 RL 方法的靈活性和穩定性,因此探索新的研究方向可能短期內無法獲得明顯的收益。因此谷歌介紹了一款基於 TensorFlow 的新框架,旨在為強化學習研究者及相關人員提供具備靈活性、穩定性及複現性的工具。
項目地址:https://github.com/google/dopamine
該框架的靈感來自於大腦中獎勵–激勵行為的主要組成部分「多巴胺」(Dopamine),這反映了神經科學和強化學習研究之間的密切聯繫,該框架旨在支持能夠推動重大發現的推測性研究。
除了谷歌發布的這種具有易用性和可複用性的 RL 框架,在強化學習領域中,OpenAI 還發布了 Spinning Up。它是一份完整的教學資源,旨在讓所有人熟練掌握深度強化學習方面的技能。Spinning Up 包含清晰的 RL 代碼示例、習題、文檔和教程。

項目地址:https://spinningup.openai.com/en/latest/
圖網絡庫(Graph Nets library)
DeepMind 開源的這個項目主要是依據他們在 6 月份發表的論文《Relational inductive biases, deep learning, and graph networks》,他們在該論文中將深度學習與貝葉斯網絡進行了融合,並提出了一種具有推理能力的概率圖模型。
項目地址:https://github.com/deepmind/graph_nets
圖網絡庫可以用 TensorFlow 和 Sonnet 快速構建圖網絡,它還包含一些 demo,展示了如何創建、操作及訓練圖網絡以在最短路徑搜索任務、排序任務和物理預測任務中進行圖結構數據推理。每個 demo 使用相同的圖網絡結構,該結構可以凸顯該方法的複雜性。

圖神經網絡框架 DGL
目前擺在深度學習面前有一個很現實的問題,即如何設計「既快又好」的深度神經網絡?也許更加動態和稀疏的模型會是答案所在。可見,不論是數據還是模型,「圖」應該成為一個核心概念。
基於這些思考,NYU、AWS 開發了 Deep Graph Library(DGL),一款面向圖神經網絡以及圖機器學習的全新框架。
項目地址:https://github.com/jermainewang/dgl
目前 DGL 提供了 10 個示例模型,涵蓋了單靜態圖、多圖和巨圖三種類別。其中除了 TreeLSTM,其余都是 2017 年以後新鮮出爐的圖神經網絡,其中包括幾個邏輯上相當複雜的生成模型(DGMG、JTNN)。他們還嘗試用圖計算的方式重寫傳統模型比如 Capsule 和 Universal Transformer,讓模型簡單易懂,幫助進一步擴展思路。
Auto Keras
AutoKeras 是一個由易用深度學習庫 Keras 編寫的開源 Python 包。AutoKeras 使用 ENAS——神經網絡自動架構搜索的高效新版本。AutoKeras 包可通過 pip install autokeras 快速安裝,然後你就可以免費在準備好在的數據集上做你自己專屬的架構搜索。
項目地址:https://github.com/jhfjhfj1/autokeras
因為所有的代碼都是開源的,所以如果你想實現真正的自定義,你甚至可以利用其中的參數。所有代碼都來自 Keras,所以代碼深入淺出,能幫助開發人員快速準確地創建模型,並允許研究人員深入研究架構搜索。
TransmogrifAI
軟體行業巨頭 Salesforce 開源了其 AutoML 庫 TransmogrifAI。TransmogrifAI 是一個基於 Scala 語言和 SparkML 框架構建的庫,只需短短的幾行代碼,數據科學家就可以完成自動化數據清理、特徵工程和模型選擇工作,得到一個性能良好的模型,然後進行進一步的探索和迭代。
項目地址:https://github.com/salesforce/TransmogrifAI
TansmogrifAI 為我們帶來了巨大的改變,它使數據科學家在生產中使用最少的手動調參就能部署數千個模型,將訓練一個性能優秀模型的平均時間從數周減少到幾個小時。
最後,AutoML 類的工作在 18 年還有很多,不過要分清楚這些概念,可以讀一讀下面的文章:
目標檢測框架 Detectron
今年 Facebook 開源的目標檢測框架 Detectron 目前已有超過 1.8W 的收藏量,它構建於 Caffe2 之上,目前支持大量頂尖目標檢測算法。其中包括 Mask R-CNN(ICCV 2017 最佳論文)和 Focal Loss for Dense Object Detection(ICCV 2017 最佳學生論文)。
項目地址:https://github.com/facebookresearch/Detectron
目前 Detectron 已經包括檢測、分割和關鍵點檢測等眾多任務的頂尖算法,且一旦訓練完成,這些電腦視覺模型可被部署在雲端或移動設備上。下圖展示了 Model Zoo 中 Mask-R-CNN 關鍵點檢測的基線結果,它還有很多任務與模型。