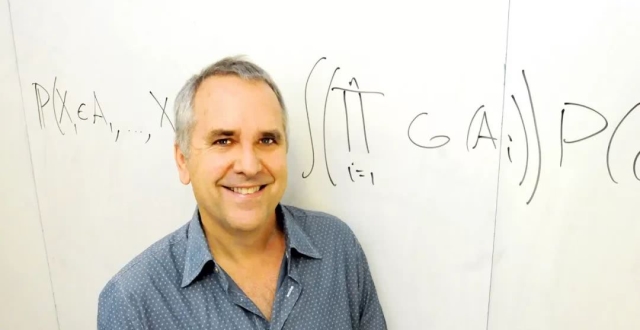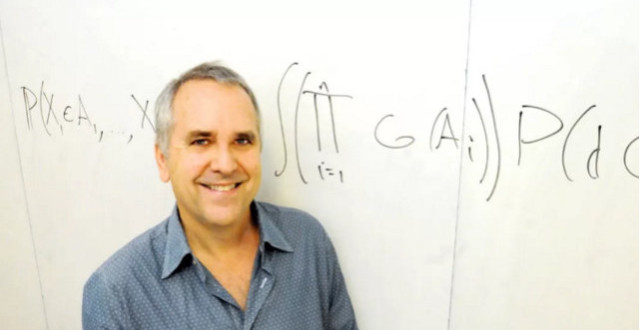點擊筆記俠關注 回復“1”領取100套知識卡片大禮包

內容來源:本文摘編湛廬文化出品書籍《AI的25種可能》書評文章,本書作者約翰.布羅克曼(John Brockman) ,筆記俠經出版社授權發布。
封面設計 &責編| 麗麗
第 4287篇深度好文 : 5133 字 | 8 分鐘閱讀
讀書筆記•人工智能
本文優質度:★★★★★+口感:蔓越莓
筆記君說:
世界上最聰明的網站Edge,每年一次,讓100位全球最偉大的頭腦坐在同一張桌子旁,共同解答關乎人類命運的同一個大問題,開啟一場智識的探險,一次思想的旅行!
人工智能是今天的神話,也是其他一切故事背後的故事。本書集結了諸多來自人工智能領域內外的重要思想家的對話,探討了人工智能的定義及含義。
以下,enjoy~~
世界上最聰明的網站Edge,每年一次,讓幾十位全球最偉大的頭腦坐在同一張桌子旁,共同解答關乎人類命運的同一個大問題,開啟一場智識的探險,一次思想的旅行!
這次,25位頂尖思想家們將話題聚焦到了人工智能,他們的思想集結成了《AI的25種可能》一書。
《AI的25種可能》集結了包括史蒂芬·平克、朱迪亞·珀爾、丹尼爾·丹尼特、邁克斯·泰格馬克等25位計算機科學家、心理學家、物理學家、科技史學家的前沿洞見,AI的25種可能,就是人類未來的25種可能。
一、朱迪亞·珀爾
不透明學習機器的局限性
當前的機器學習系統幾乎完全在統計模式或者說模型盲(model-blind)的模式下運行,這在許多方面類似於將函數擬合到大量點數據。
這樣的系統不能推理“如果……會怎樣?”的問題,因此不能作為強人工智能的基礎,強人工智能是模擬人類推理和能力的人工智能。
為了達到人類智能水準,學習機器需要現實藍圖的指導,這種藍圖是一個模型,類似於當我們在陌生城市開車時給我們指路的道路地圖。
我認為機器學習是一種工具,使我們從研究數據走到研究概率。但是,從概率到實際理解,我們仍然需要多邁出兩步,非常大的兩步。
一是預測行動的結果。
第一層是統計推理。統計推理能告訴你的,只是你看到的一件事如何改變你對另一件事的看法。例如,某症狀能告訴你得了哪一種疾病。然後,是第二層。第二層包含了第一層,但第一層卻不包含第二層。
第二層處理的是行動。“如果我們抬高價格會怎樣?”“如果你讓我笑了,會怎樣?”第二層需要的是乾預信息,這些信息是第一層所沒有的。這些信息可被編碼成概率圖模型,它僅僅告訴我們哪個變量對另一個變量有響應。
二是反事實想象。
“如果這個東西重兩倍,會怎樣?”“如果當初我沒有這樣做,會怎樣?”“治好了我頭疼的是阿司匹林還是剛剛打的盹?”反事實在感覺中屬於最高層次,即使我們能夠預測所有行動的結果,但卻無法得到反事實。
它們需要一種額外的東西,以等式的形式告訴我們對於其他變量發生的變化,某個變量會如何反應。
因果推理研究的一個突出成就是對乾預和反事實的算法化,也就是對層級結構最高兩層的算法化。
當我思考機器學習的成功並試圖把它推廣到未來的人工智能時,我問自己:“我們是否意識到了在因果推理領域中發現的基本局限性?我們準備繞過阻礙我們從一個層級升到另一個層級的理論障礙嗎?”
所以我認為,數據科學只是一門有助於解釋數據的科學,而解釋數據是一個兩體問題,將數據與現實聯繫起來。
但無論數據有多“大”,人們操控數據多麽熟練,數據本身並不是一門科學。不透明的學習系統可能會把我們帶到巴比倫,但絕不是雅典。
二、史蒂芬·平克
在不理智的頭腦想象區,總是很容易想象出災難場景
今天許多科技預言的一個焦點是人工智能,在原始的反烏托邦科幻作品中,計算機瘋狂地運行並奴役人類,人類無法阻擋它們的控制;
而在更新的版本中,它們偶然地征服了人類,一心一意地尋求我們賦予的目標,儘管會對人類福祉產生副作用。
無論是在哪個版本中,人工智能都是焦點。
不過,我還是覺得這兩種威脅都是虛構的,因為它源於一種狹隘的技術決定論,這種技術決定論忽略了在像計算機或大腦這樣的智能系統以及整個社會中的信息和控制網絡。

這種對征服的恐懼來自對智能的模糊理解,其模糊之處在於將智能歸於一種存在之鏈和尼采式的權力意志,而不是根據信息、計算和控制對智能和目的進行的維納式分析。
在這些恐怖場景中,智能被描繪成一種全能的、能實現願望的神藥,智能主體各自擁有不同數量的這種神藥。
人類比動物擁有更多的神藥,而人工智能的計算機或機器人比人類擁有的更多。
既然我們人類曾用我們不高不低的智能馴養或消滅了那些不太有智能的動物,既然技術先進的社會奴役或消滅了技術水準很低的社會,那麽超級聰明的人工智能也會對我們人類做同樣的事情。
但是這些場景混淆了智能與動機、信念與欲望、推理與目標、圖靈闡明的計算和維納闡明的控制。
即使我們發明了超人智能機器人,他們為什麽要奴役他們的主人或接管世界?智能是指運用新的手段達到目標的能力。但是這些目標與智能無關,因為聰明並不等同於一定要追求某些東西。
巧合的是,智人的智能是達爾文自然選擇的產物,而自然選擇本質上是一個競爭過程。
在智人的大腦中,推理與一些諸如支配對手和積累資源等目標捆綁在一起。
但是,把某些靈長類動物的邊緣腦中的回路與智能的本質混為一談是錯誤的。沒有任何一個複雜系統定律表明,智能主體一定會變成無情的自大狂。
三、邁克斯·泰格馬克
通用人工智能的真正風險不是它的惡意,而是它的能力
許多思想家把超級智能這個概念貶低為科幻小說,因為他們認為智能是一種神秘的東西,只能存在於生物有機體,尤其是人類中,他們還認為這種智能從根本上限制了今天的人類能做什麽。
但是,從我作為物理學家的角度來看,智能只是由四處移動的基本粒子所進行的某種信息處理,沒有任何物理定律表明人類不能製造出在任何方面都比我們具有更高級智能的機器,這種機器能孕育宇宙生命。
這表明,我們僅僅看到了智能的冰山一角,存在這麽一種驚人的可能性:
也許我們能釋放出自然界中所蘊藏的全部智能,利用它來幫助人類繁榮發展,或掙扎求生。
真正的問題是,人工智能安全研究必須在嚴格的期限內進行:在通用人工智能到來之前,我們需要弄清楚如何讓人工智能理解、采納和保留我們的目標。
機器越智能、越強大,使它們的目標與我們的目標一致就越重要。
只要我們製造的機器相對愚蠢,那麽問題便不是人類的目標是否會佔上風,而是在達到我們與機器目標一致之前,機器會造成多少麻煩。
然而,如果製造出超級智能,那麽情況就會反過來:因為智能就是實現目標的能力,所以超級智能人工智能從定義上來說,比起我們人類實現自己的目標,它更擅長完成它的目標,因此會佔上風。
換句話說,通用人工智能的真正風險不是它的惡意,而是它的能力。
一個擁有超級智能的通用人工智能將非常擅長完成它的目標,如果這些目標與我們人類的不一致,我們就有麻煩了。
為修建水力發電大壩需要淹沒蟻丘,對這件事,人類不會反覆三思,所以我們不要把人類置於螞蟻的位置。
大多數研究人員認為,如果我們最終創造了超級智能,我們應該確保它是人工智能安全先驅埃利澤·尤德考斯基所稱的“友好的人工智能”,其目標在某種深層意義上是有益的。
四、塞思·勞埃德
雖然AI有了長足的發展,但機器人“還是不會系鞋帶”
我們不應該完全相信技術奇點一說,預測技術進步的常見困難以及發展超級智能時特有的問題都應該讓我們警惕,不要高估信息處理的力量和效能。
沒有任何一種指數式增長能一直持續下去。原子彈爆炸呈指數式增長,但也就持續到燃料耗盡之時。
同樣地,摩爾定律的指數式增長近來開始進入基礎物理所設定的極限之中。
計算機的時鐘速度在 15 年前不超過幾千兆赫,僅僅是因為速度再高芯片就開始熱得熔化了。
由於隧道效應和電流泄漏,晶體管的小型化已經進入量子力學領域。
最終,摩爾定律驅動的各種記憶體和處理器的指數式增長都將停止。然而,再過幾十年,計算機的原始信息處理能力也許就能與人類的大腦匹敵,至少按照每秒處理的比特率和位翻轉粗略計算的話是如此。
人類的大腦構造複雜,經過幾百萬年的自然選擇變成了現在的樣子。越來越敏感的儀器和成像技術表明,我們的大腦在結構和功能上遠比維納所能想象的更多樣、更複雜。
最近,我問現代神經科學先驅托馬索·波焦(Tomaso Poggio),是否擔心隨著計算機處理能力的快速提高,計算機將很快趕上人類的腦。“絕不可能。”他回答。
對奇點主義的恐懼,主要是擔心隨著計算機更多地參與設計它們自己的軟體,它們將迅速擁有超人的計算能力。
但機器學習的真實情況卻恰恰相反。當機器的學習能力變得越來越強時,它們的學習方式會變得越來越像人類。
許多事例表明,機器的學習是在人類和機器老師的監管下進行的。對計算機進行教育就像對青少年進行教育一樣困難、緩慢。
因此,基於深度學習的計算機系統正在變得越來越人性化。它們帶來的學習技能不是“優於”而是“補充”人類學習:計算機學習系統可以識別人類無法識別的模式,反之亦然。
世界上最好的國際象棋棋手既不是計算機,也不是人類,而是與計算機合作的人。
網絡空間裡確實存在有害的程序,但這些主要是惡意軟體,即病毒,它們不是因為其超級智能而為世人所知,而是因為惡意的無知而遭世人譴責。
五、我們缺少的是人類的良好模型,
機器學習的關鍵必然是人類的學習
價值對齊,就是使自動化智能系統的價值與人的價值對齊。在人工智能研究中,價值對齊只是一個小的主題,但對它的研究日漸增加。用於解決這個問題的一個工具就是反向強化學習。
強化學習是訓練智能機器的一種標準方法。通過將特定的結果和獎勵聯繫起來,可以訓練機器學習系統遵循產生特定結果的策略。
現代機器學習系統可以通過應用強化學習算法找到非常有效的策略來玩電腦遊戲,從簡單的街機遊戲到複雜的實時策略遊戲。
反向強化學習扭轉了這種途徑:通過觀察已經學習了有效策略的智能主體的行為,我們可以推斷導致這些策略發展的獎勵。

最終,我們需要的是一種方法,它能描述人類思維的運作原理,具有理性的普遍性和啟發式的準確性。
實現這一目標的一種方法是從合理性開始,考慮如何讓它朝現實的方向發展。
把合理性作為描述任何現實世界行為的基礎,這就存在一個問題,那就是,在許多情況下,計算合理行為需要主體擁有大量的計算資源。
如果你正在做出一個非常重要的決定,並且有很多時間來評估你的選擇,那麽花費這些資源也許是值得的,但是人類的大多數決定都是快速做出的,而且風險相對較低。
無論在什麽情況下,只要你做出決定花費的時間成本很昂貴(至少因為你可以把這些時間花在別的事情上),理性的經典概念就不再能很好地描述一個人該如何行事。
超級智能人工智能還有很長的路要走。在過去幾年裡,對視覺和語言的模型開發已經創造出了用於解釋圖像和文本的重要的商業新技術,而人類仍然是我們在製造思考機器時要參考的最好例子,所以我認為開發良好的人類模型將是下一個研究領域。
六、丹尼爾·希利斯
超級智能不僅僅包括人類,它們是人類和信息技術的混合體
今天,如果沒有計算機網絡、數據庫和決策支持系統,所有的系統都無法運作。
這些混合智能是技術增強的人類網絡。這些人工智能具有超人的能力。它們比人類個體懂得更多;它們能夠感知更多;
它們能夠做出更精細的分析和更複雜的計劃。它們擁有的資源和力量比任何個人擁有的都要多。

雖然我們並不總能察覺到,但是諸如民族國家和企業這樣的混合型超級智能有它們自己的湧現目標。
雖然它們是由人類建造的,也是服務於人類的,但它們的行為卻常常像獨立的智能實體一樣,而且它們的行為並不總是與創造它們的人的利益相一致。
國家並不總是為公民服務,公司也不總是為股東服務。非營利組織、宗教組織或政黨也不總是遵循其原則而行動。
直覺上,我們意識到它們的行為受其內部目標的引導,這就是為什麽我們在法律上和思維習慣上都把它們人格化。
當我們談論“中國想要什麽”或“通用汽車正在做什麽”時,我們並不是在隱喻。這些組織有智能,它們能感知、能做出決定、能采取行動。
和人類個體的目標一樣,組織的目標也很複雜,常常還自相矛盾,但它們的目標是真正的目標,因為這些目標能指導行動。
這些目標在某種程度上取決於組織中人員的目標,但兩者並不相同。
政府和公司,兩者結構中都有一部分是由人類建立的,兩者都會自然而然受到人類的激勵,至少會表現出與它們所依賴的人類有共同的目標。
離開人類,它們都無法運轉,所以它們需要與人類合作。當這些組織表現出利他行為時,通常這就是它們的一部分動機。
總之,這些混合機器有目標,它們的公民、客戶、雇員是它們用來實現目標的資源。我們幾乎能夠不用人類組件,隻用純信息技術構建超級智能。這就是人們通常所說的人工智能。
*文章為講者獨立觀點,不代表筆記俠立場。
精彩活動推薦