智東西(公眾號:zhidxcom)
編 | 韋世瑋
導語:近期,麻省理工學院(MIT)和IBM的研究人員分別發表了兩項研究成果,用AI來輔助人們在臨床醫學和神經科學領域的研究和發展。
智東西7月8日消息,最近,有兩項分別來自麻省理工學院和IBM的研究,利用人工智能幫助人們進行神經科學領域的研究,進一步幫助人們加速對人類大腦的理解。
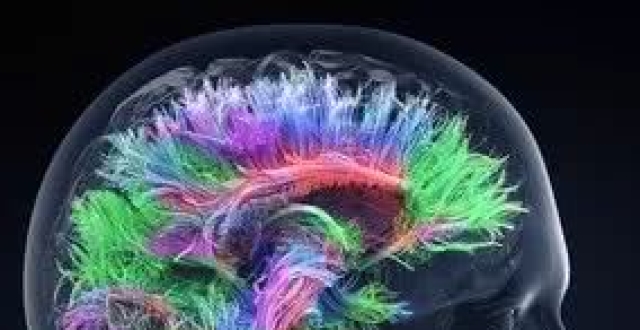
一方面,麻省理工學院的研究人員正在訓練機器學習模型,研究從單個分割的大腦掃描圖像和未標記的掃描圖像中,分割大腦解剖結構,從而使用人工智能實現神經科學圖像分割的自動化。
另一方面,IBM的研究人員創建了一個基於雲端的神經科學模型,用於研究神經退行性疾病(由大腦和脊髓的神經元或髓鞘的喪失所致,並隨著時間推移而惡化,導致出現功能障礙),並使用模擬生物進化的算法來解決複雜問題。
一、卷積神經網絡為卡牌實時提供信息
在前段時間舉行的模式識別與計算機視覺大會(Conference on Computer Vision and Pattern Recognition)上,來自麻省理工學院的一組研究人員提出了一種創新的人工智能系統。
該系統可以學習從單個分段腦掃描圖像和未標記的掃描圖像中,分割解剖腦結構,實現自動化神經科學圖像分割。
這種用於神經科學的新型人工智能系統,是基於一款發行於1993年的著名集換式卡牌遊戲(Collectible card game)《魔法風雲會(Magic:The Gathering)》而研發。
Amy Zhao是麻省理工學院電氣工程與計算機科學系(EECS),以及計算機科學與人工智能實驗室(CSAIL)的研究生,同時也是該項研究的第一作者。
最初,她嘗試使用一個由卷積神經網絡(CNN)技術創建的應用程序,根據智能手機拍攝的照片,實時為《魔法風雲會》中的紙牌提供卡牌的類別、屬性和施放費用等詳細信息。
這項技術的挑戰在於,計算機視覺任務需要一組照片數據集,該數據集不僅包含20,000張遊戲卡牌,而且還包含每張卡牌的不同拍攝外觀和拍攝屬性(如照明)的圖片版本。
但是,手動創建這樣的一個數據集需要花費大量的實踐和精力,因此Amy開始通過合成數據集中所有卡牌的變形版本,來自動創建數據集。
卷積神經網絡是一種深度學習算法,具有人工神經網絡結構,該算法受生物大腦視覺皮層的啟發,用一小部分數據進行訓練。
Amy使用200張卡牌,每張卡牌分別搭配10張照片,讓卷積神經網絡經過訓練,學習如何判斷卡牌的所處的不同位置和照片外觀,如亮度、反射和照片角度,從而能夠合成數據集內所有卡牌的真實變形版本組。
二、卷積神經網絡分析腦圖像的過程
Amy發現,這種變形的方法可以應用於磁共振成像(Magnetic Resonance Imaging,簡稱MRI)中。磁共振成像是斷層成像的一種,能夠利用磁共振現象從人體中獲得電磁信號,並重建出人體信息。
人工智能深度學習的模式識別功能是機器學習的一個子集,它幫助神經科學家對腦圖像進行複雜的分析。然而,訓練該機器學習算法是一個昂貴的、勞動密集型的挑戰。
一方面,對於神經科學研究,訓練機器學習通常需要神經科學家在每一次的腦部掃描中,手動對解剖結構進行數據標記。
另一方面,圖像分割是基於共享特徵對圖像像素進行標記的過程,而磁共振成像的圖像又是一個以三維像素形式呈現的體素。
因此,神經科學的研究人員經常需要根據大腦的解剖結構,對體素區域進行分離和標記,手工進行圖像分割。
Amy與麻省理工學院博士後助理Guha Balakrishnan、Frédo Durand教授、John V. Guttag教授,以及資深作家Adrian V. Dalca,使用單一標記的分段腦MRI掃描和一組100個未標記的病人掃描,完成了自動化神經科學圖像分割過程。
在研究過程中,研究人員使用了兩個卷積神經網絡。
首先,卷積神經網絡從100個未標記的掃描中學習亮度、對比度、噪聲和空間變換流場(指運動流體所佔的空間區域裡的速度、壓強等因素)的變化,這些變化模擬了掃描之間的體素運動。
其次,為了合成新的標記掃描,系統生成一個隨機的流場,並將這個隨機的流場應用於標記的MRI掃描,以匹配未標記掃描數據集中實際患者的MRI。然後,系統將所學習到的亮度、對比度和噪聲變化進行隨機組合。
最後,系統根據提速運動的流場,將標簽標記到合成掃描的圖像中。這些合成的掃描圖像將被輸入到一個單獨的卷積神經網絡,以便訓練該卷積神經網絡學習如何分割新的圖像。
三、該框架可合成逼真多樣的標記實例
此外,研究小組對30種大腦結構的圖像分割系統進行了100次掃描,並將其與現有的自動和手動分割方法進行了比較。結果表明,該方法與現有的圖像分割方法相比有了顯著改進,特別是在海馬體等較小的大腦結構方面。
研究人員在論文中表示,在他們的測試集中,分割器在每個例子上都比現有的單次分割方法做得更好,接近完全監督模型的性能(之前大多是半監督的)。該機器學習框架可在多個醫學領域應用,比如臨床設置,在臨床設置中由於時間限制,通常只允許手工注釋少量掃描。
對此,麻省理工學院的研究人員表明,通過機器學習從未標記的大腦掃描圖像中,獨立的空間和外觀轉換模型,可以合成逼真多樣的標記實例。
另外,系統生成的合成示例可以用來訓練性能等於甚至優於當前圖像分割方法的分割模型,這也是為什麽《魔法風雲會》能催生一種可訓練人工智能深度學習算法的新方法。

四、什麽是進化算法?
最近,IBM的研究人員在《細胞報告(Cell Reports)》和《今日心理學(Psychology Today)》上發布了一種創新方法,通過利用進化算法創建了一個基於雲端的神經科學模型,可用於研究神經退行性疾病。
在神經科學和人工智能的交叉領域,是深度學習的另一種方法。深度學習是鬆散地建立在生物大腦的神經網絡層上的,它往往是單一用途的單點解決方案,需要將大量數據集進行廣泛訓練,並針對特定的環境進行定製。
相比之下,進化算法(Evolutionary Algorithms,簡稱EA)則簡單得多。它是進化計算的一個子集,能夠模擬生物進化來解決複雜問題。另外,它基於“適應度”函數中設置的標準來解決問題,幾乎不需要數據。
不同類型的進化算法包括遺傳算法、進化策略、差分進化和分布估計算法,它們的共同之處在於進化的過程,該過程通常包括隨機生成搜索點種群,也稱為代理,染色體、候選解或個體。
這些搜索點種群會經歷多代的變異操作和選擇,而變異操作類似於生物突變和重組過程。
每次種群迭代後,進化算法將計算每個搜索點的適應度,並保留最強(較高的目標值)的搜索點,刪除最弱(較低的目標值)的搜索點。
通過這種方式,搜索點的種群經過幾代人的進化,將產生解決問題的最佳方案,而適者生存的變異依然存在。
五、基於雲端創建神經科學模型
進化算法在本質上是分布式的,這使得它非常適合基於雲端或大規模並行的多核處理。
在這項針對亨廷頓舞蹈病(Huntington’s disease)的神經科學研究中,研究人員使用了IBM Cloud上的一種最新的非主導排序差異進化(NSDE)算法。
參與這項研究的IBM主發明人、神經科學家James R. Kozloski表示,他們引入了誤差函數的軟闕值和鄰域懲罰,以防止由於目標是精確的特徵值而導致的系統偏差。
Kozloski表示,他們使用NSDE框架來修正誤差,並根據先前選擇的0個誤差模型的特徵空間和“擁擠度”進行懲罰,從而使算法盡可能均勻地覆蓋0個錯誤區域。這讓他們能夠創建適合數據的各種參數模型,而不僅僅是單一模型。
該項研究的算法設計大師Tim Rumbell博士和Thomas J. Watson研究中心的計算神經學家表示,這個算法最終將幫助模型進行推廣,因為他們支持算法尋找一個參數空間區域,該區域能生成像實驗期間所有神經元一樣響應的模型。
結語:促進人們對人類大腦的科學理解
麻省理工學院的研究人員通過卷積神經網絡分析腦圖像,以及IBM的研究人員利用進化算法創建了一個基於雲端的神經科學模型,這兩項研究都是人工智能技術在神經科學領域的發展和應用。
未來,當這兩項研究進一步成熟和真正落地後,也許將有益於臨床醫學和神經科學研究的發展,進一步加速人們對人類大腦的科學理解。
文章來源:AI Trends、Psychology Today